Günstigere Modelle bedeuten nicht automatisch günstigere Agenten. Gestern haben wir ECC (Everything Claude Code) als Harness-Schicht betrachtet: weniger Umwege, klarere Guardrails, Constraints über Sessions hinweg. Der Harness steuert wie gearbeitet wird—jede Inferenzrunde, jeder Tool-Call und jedes wachsende Kontextfenster verbraucht trotzdem Compute und Zeit.
Heute rücken wir eine Ebene tiefer: Was ist τ, und warum geht es Agent-Betreibern an die Rechnung? Mit diesem Bild werden Agent-Hunger, Jevons-Nachfrage, Memory-/Kommunikationswand und Lingqu als Ziel „unsichtbarer“ Latenz zu einer zusammenhängenden Geschichte.
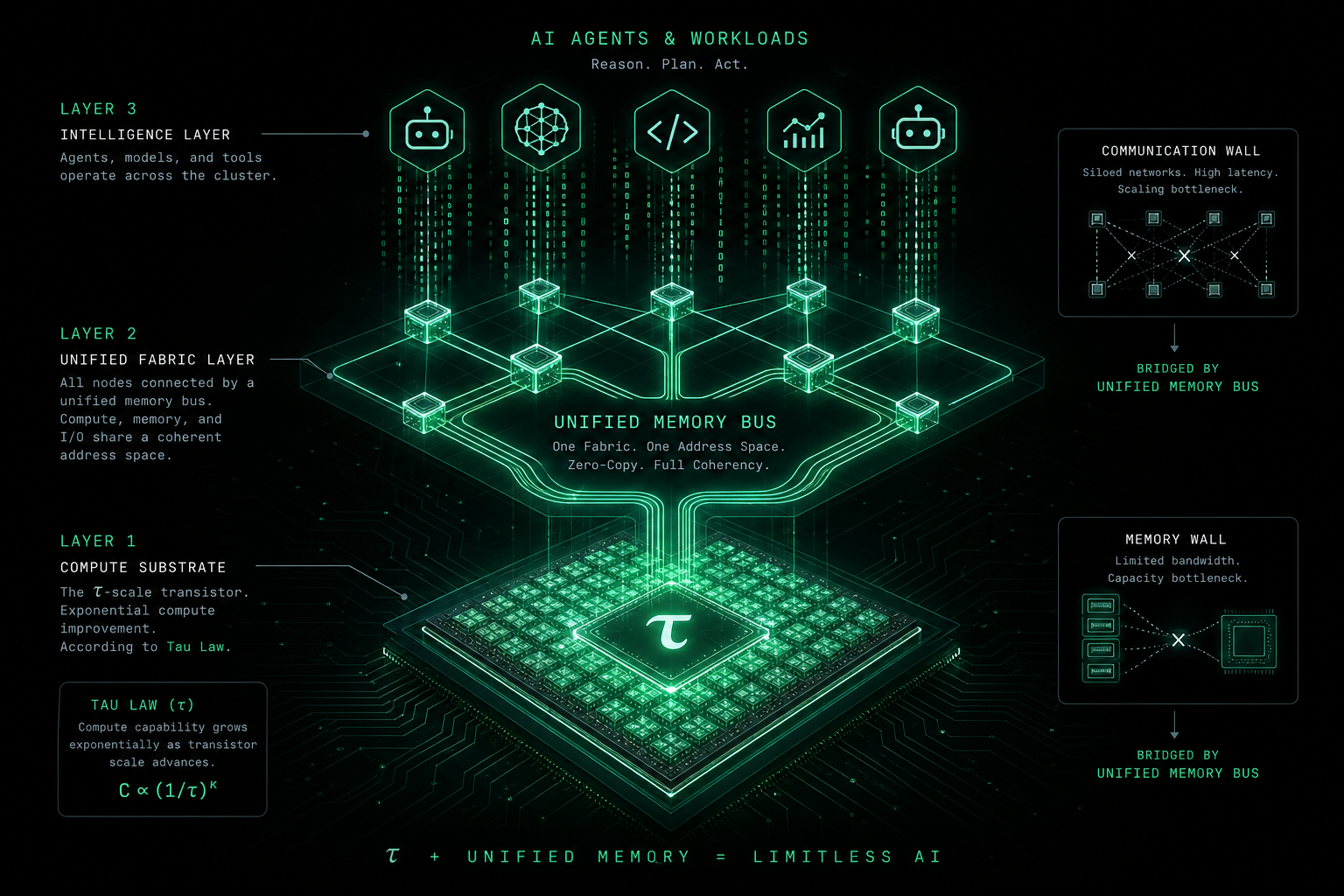
Zuerst τ: Was meint man mit dem „τ-Gesetz“?
In der aktuellen KI-Infrastruktur-Debatte taucht τ (Tau, griechisch) oft neben 韬 (tāo) auf—das 韬-(τ)-Gesetz. Als Primärquelle zu τ Scaling eignet sich Huaweis IEEE-ISCAS-2026-Meldung (nachhaltige KI-Compute-Versorgung, Systemhomogenität). Es ist keine festgeschriebene Physikformel und kein Ersatz für das Moore-Gesetz in einem Satz, sondern eher eine langfristige Lieferseiten-These in drei Punkten:
- Transistoren bzw. äquivalente Recheneinheiten werden dichter und billiger. Prozess und Packaging drücken effektive Rechenleistung pro Dollar.
- Dichte wird gleichmäßiger und skalierbarer. Nicht nur Peak-FLOPS, sondern Compute, Speicher und Interconnect als poolbare Ressource großer KI-Flotten.
- Wettbewerb verschiebt sich von „Haben wir Beschleuniger?“ zu „Laufen die ausgelastet?“ Nameplate-FLOPS steigen—hängen Bandbreite und Fabric hinterher, bleibt es langsam und teuer.
Moores Gesetz (grober Transistorverdopplungsrhythmus) beschreibt vor allem wachsende Integration. Die τ-Erzählung in Whitepapers betont nachhaltige, homogenere KI-Compute-Versorgung: Wie viele effektive Trainings- oder Inferenz-Tokens kauft ein Euro—und trägt das dauerhafte, bandbreitenhungrige Agenten- und Trainingslasten? Der Huawei-Beitrag oben dreht sich um τ Scaling; dieser Artikel knüpft daran für Agent-Szenarien an, ohne offizielle Herstellerdefinitionen zu ersetzen.
| Vergleich | Moore (klassisch) | 韬-(τ)-Gesetz (Industrie) |
|---|---|---|
| Fokus | Transistoren pro Chip | Compute-Kosten pro Einheit und Skalierbarkeit für KI |
| Typische Frage | „Wann die nächste Fertigungsnode?“ | „Mehr Tokens / größerer Cluster im gleichen Budget?“ |
| Für Agenten | Indirekt—Chips werden stärker | Direkt—API-Preise können fallen, Nutzung wächst schneller |
| Allein nicht gelöst | Memory Wall, Fabric, Software | Braucht Lingqu-artigen Unified Bus |
Praktisch reichen drei Merksätze—ohne Formel:
- Lieferseite: Langfristig kauft derselbe Dollar tendenziell mehr Compute—Voraussetzung dafür, dass „Compute als Macht“ sich verteilen kann.
- Nachfrageseite: Agenten machen aus „mal kurz fragen“ „stundenlang Tools schleifen“—Kosten = Preis × Menge, Menge oft superlinear.
- System: τ verbessert „wie viel Rechnen auf dem Die“; Memory- und Kommunikationswand brauchen Unified Bus (z. B. Lingqu) und Software—sonst: schnellere Chips, trotzdem Leerlauf.
Im Text: Agent-Hunger → Jevons bei fallenden Stückpreisen → Wände → Lingqu → Cloud-Mac + Harness für macOS-Teams.
1. Warum moderne Agenten „gierig“ sind
Klassische Copilot-Vervollständigung ist Einmal-Inferenz. Claude Code, Codex CLI, Cursor Agent werden zu Dauerlast: Plan → Dateien → Shell → Ergebnis → neu planen—mit wachsendem Kontext pro Runde.
| Dimension | Chat / Completion | Coding-Agenten |
|---|---|---|
| Muster | Ein Frage-Antwort-Paar | plan → tool → re-infer (Schleife) |
| Kontext | Datei oder Kurzsnippet | Repo, Memory, Terminal-Logs |
| Fehler | Zeile neu | Ganze Pipeline neu—Token explodieren |
| Dauer | Sekunden | Minuten bis Stunden |
| Harness | — | Weniger Müll-Runden—jede Runde rechnet |
Die Nachfrage wird „Dauerbetrieb + viele kleine Requests“. Training will Cluster-FLOPS; Produktions-Agenten zahlen Tail-Latenz—Modell, Tools, RTT, Disk. ECC kürzt Leerlauf, nicht die fünfzig notwendigen Runden.
2. τ drückt den Stückpreis—warum steigt die Summe?
Hält die τ-Kurve, kauft man langfristig mehr Inferenz pro Dollar. Agent-Nachfrage wirkt superlinear:
- Billigere Modelle → ganze Repo-Refactors, volle Testmatrizen an Agenten;
- Reife Harnesss → 7×24-Jobs wie OpenHuman und OpenClaw-CI;
- Größere Kontextfenster → Input- und Output-Tokens wachsen parallel.
„Compute ist Macht“ beschreibt die Rechnungsstruktur: Wer dauerhaft GPU/API-Kontingente stemmt, automatisiert feiner. τ senkt den Token-Preis, nicht zwingend die verbrannten Tokens pro Engineer und Tag.
3. Memory Wall und Communication Wall: teuer ist auch das Warten
In Trainings- und Inferenz-Clustern ist der Engpass selten nur „Peak-FLOPS einer Karte“. Zwei „Wände“ tauchen in Papers und Whitepapers immer wieder auf:
3.1 Memory Wall
Rechenleistung wächst historisch schneller als Speicherbandbreite. Beschleuniger warten auf Daten—Gewichte, Aktivierungen, KV-Cache. MFU bleibt niedrig; gekaufte FLOPS rotieren leer. Bei Inferenz frisst Langkontext-KV VRAM—Speicher wird vor Mathe zum Engpass.
3.2 Communication Wall
Multi-GPU-Training lebt von Gradientensync, Tensor-Parallel, MoE—Links innerhalb und zwischen Knoten. Üblicher Stack:
- PCIe zwischen CPU und Beschleunigern—begrenzte Bandbreite, kopielastige Semantik;
- NVLink / Intra-Node-Fabrics—stark in einer Box, schwächer über Maschinengrenzen;
- Ethernet / InfiniBand—guter Scale-out, aber AllReduce kann einen großen Bruchteil eines Steps fressen (oft ~30 % je nach Topologie—variiert).
Bei Coding-Agenten: Modell in der Cloud, Tools lokal—jeder run_terminal_cmd und Repo-Lesezugriff zahlt RTT × Anzahl. Andere Schicht als NVLink, gleiche „Latenzsteuer“. Harness hebt die Physik nicht auf.
[App] Agent / Harness (ECC) → weniger Leerlauf-Runden
[System] Unified Bus / Speicher → weniger Kopien, weniger Sync
[Silizium] τ-Dichte → mehr Rechenleistung pro Watt
↓ Produkt = Multiplikation
4. Lingqu und „unsichtbare“ Latenz: wo τ den System-Stack trifft
τ: wie günstig Compute auf dem Chip. Lingqu (灵衢) / Unified Bus: wie Software den Stack als eine Maschine nutzt. Öffentliche Narrative (mit aktuellen Whitepapers abgleichen):
- Unified-Memory-Semantik—CPU, NPU, Beschleuniger, Speicherpools näher an einem Adressraum, weniger explizite Kopien;
- Pooling und Sharing—Speicher und Compute pro Job, höhere Flottenauslastung;
- Unsichtbare Latenz als Ziel—nicht Null-Physik, aber Sync, die Pipelines verdecken.
Für Frontier-Training: nominale FLOPS × höhere Auslastung → weniger Dollar pro Run—τ auf dem Die, Lingqu auf dem Fabric, multiplikativ.
Für Agent-Produktion kaufen Sie selten einen Cluster—Sie kaufen APIs dahinter. Günstigere, stabilere Inferenz in Scale wird Ihr Preis pro Million Tokens—bevor Jevons die Nutzung wieder hochzieht.
5. Was kommt, wenn Compute und Fabric billiger werden?
Wenn Tokens billiger werden und Cluster weniger leerstehen, ist die erste Welle selten „keine Agenten“, sondern Agenten, die dauerhaft laufen, stärker parallelisieren, sich spezialisieren:
| Form | Warum | Heute |
|---|---|---|
| 7×24-Agenten | Grenzkosten niedrig genug | Cloud Mac, OpenHuman |
| Multi-Agenten | Günstige Kommunikation | ECC, OpenClaw |
| Klein lokal + groß Cloud | Häufig billig, selten schwer | Laptop + Mac mini |
| CI/CD-Agenten | Jeder Commit | macOS-Runner |
Nächste Welle: Compute wie Versorgungsleistung—Harness steuert Ausgaben, Bus und τ die Wirtschaftlichkeit.
6. Apple Silicon, Cloud-Mac, Rechnung
Die meisten Nuvcloud-Leser liefern macOS / Xcode / dauerhafte Agenten, keine GPU-Megacluster. Zwei Merksätze:
- Unified Memory am Desktop. Apple Silicon bündelt CPU, GPU, Neural Engine, RAM—erklärt Mac-mini-Tauglichkeit für manche Agent-Nebenlasten pro Watt.
- Rechnung = API + Maschinenzeit + Unterbrechungen. ECC/OpenClaw auf dauerhaftem Cloud-Mac mini: stabile Compute, feste IP, mehr Disk—weniger teure Replays durch Laptop-Zuklappen.
Hausaufgabe: gleiche Agent-Aufgabe lokal vs. Cloud, Tokens, Zeit, Retries loggen, mit Mac-mini-Preisen vergleichen. Harness (ECC) reduziert Umwege; Cloud-Mac reduziert Unterbrechungen—Branchen-τ und Lingqu senken die Kurven darunter; zusammen definieren sie, wer sich Agent-„Compute-Macht“ leisten kann.
Agenten dauerhaft online: dedizierte Cloud-Mac-mini für Compute und Latenz
τ-Kurven und Unified Bus sind Branchenthema—Sie brauchen Maschinen, die Agenten 7×24 laufen lassen. Nuvcloud M4 Mac mini: Bare-Metal-macOS, SSH/VNC, Multi-Region, Tages-/Wochen-/Monatsabrechnung—mit ECC und OpenClaw.
Echten Agent-Job tageweise testen—Nuvcloud-Tarife ansehen.