Cheaper models do not automatically mean cheaper agents. Yesterday we unpacked ECC (Everything Claude Code) as a harness layer: it helps Claude Code, Cursor Agent, and similar tools stay on task, respect guardrails, and carry constraints across sessions. Harnesses govern how work gets done—but every turn of reasoning, every tool call, and every growing context window still burns compute and clock time.
Today we move one layer down the stack and answer a prerequisite: what is τ, and why should agent operators care? Once that picture is clear, the sections on agent appetite, Jevons-style demand, memory and communication walls, and Lingqu’s role in “imperceptible latency” read as one story instead of buzzwords.
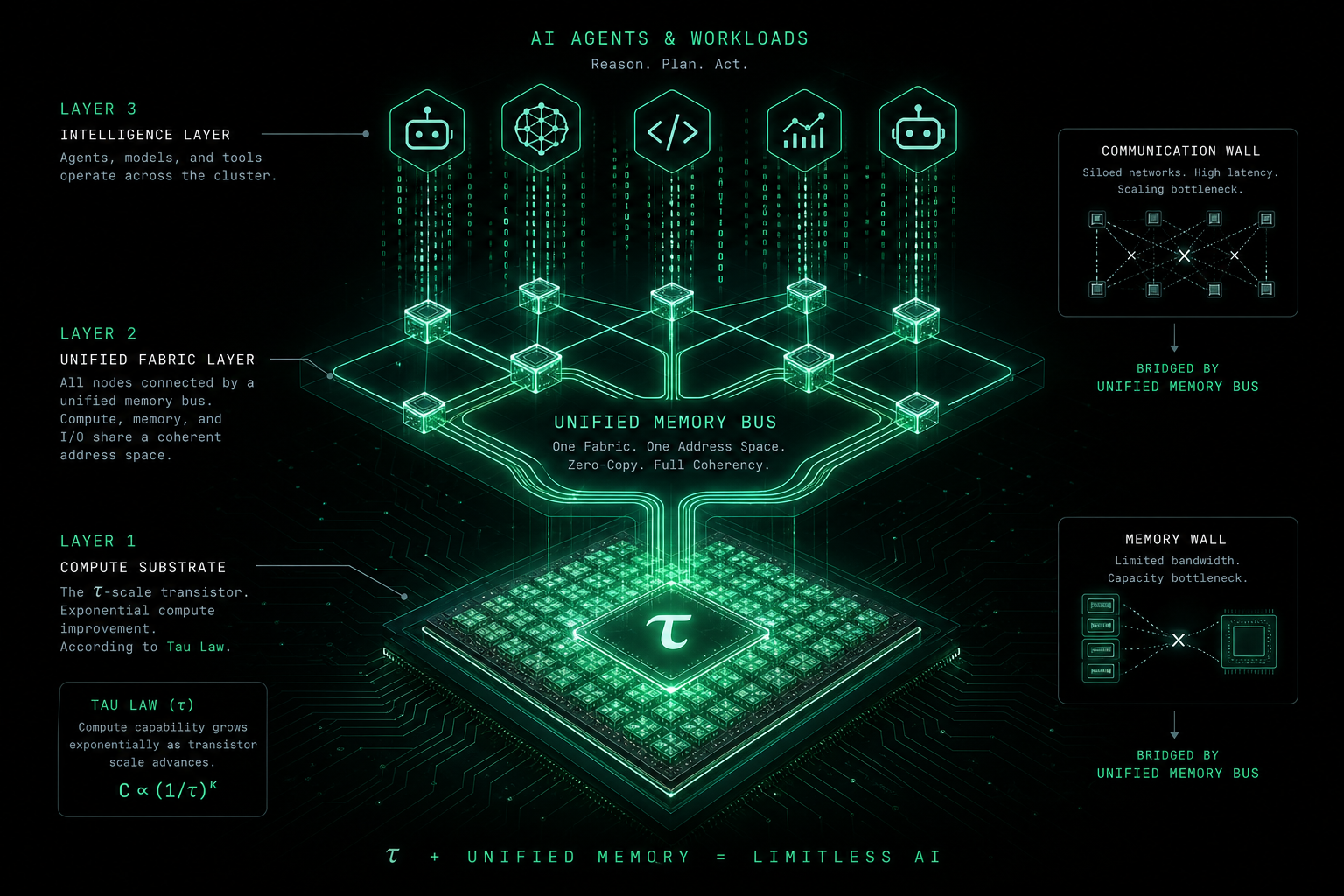
First, meet τ: what is the “tau law”?
In recent AI-infrastructure discourse, τ (tau, the Greek letter) often appears alongside the Chinese coinage 韬 (tāo)—the 韬 (τ) law. For primary context on τ Scaling, see Huawei’s IEEE ISCAS 2026 briefing (sustainable AI compute supply and system-level uniformity). It is not a textbook physics equation and not a one-line replacement for Moore’s law. It is closer to an industry shorthand for a long-run supply-side trend, usually summarized in three ideas:
- Transistors—or equivalent compute units—keep getting denser and cheaper. Process and packaging advances push more effective compute per dollar over time.
- Density trends toward uniformity and scale-out. The goal is not only peak FLOPS on a slide deck, but systems where compute, memory, and interconnect can be pooled and reused across large AI fleets.
- Competition shifts from “do we have accelerators?” to “are they actually busy?” Nameplate FLOPS climb, yet if memory bandwidth and fabric lag, users still feel slowness and sticker shock.
If you know Moore’s law (roughly: transistor count doubles every 18–24 months), treat it as the classic story of integration climbing with time. The τ narrative in public materials stresses sustainable, more uniform AI compute supply: as density rises, the industry asks how many effective training or inference tokens a dollar buys, and whether that supply can feed always-on, bandwidth-hungry workloads like agents and large-scale training. The Huawei link above centers on τ Scaling; this post builds on that framing for agent operators without replacing official vendor definitions.
| Lens | Moore’s law (classic) | 韬 (τ) law (industry narrative) |
|---|---|---|
| Focus | How many transistors fit on a die | Unit compute cost and system scale-out in AI workloads |
| Typical question | “When does the next node ship?” | “With the same budget, can we run more tokens or a bigger cluster?” |
| Implication for agents | Indirect—chips get faster over years | Direct—API list prices may fall, but usage can outrun price |
| What it does not fix alone | Memory wall, fabric limits, software efficiency | Still needs Lingqu-class unified interconnect |
For practitioners, τ’s actionable takeaway is simple—no formula required:
- Supply side: Over the long run, the same dollar tends to buy more compute (or token quota)—a precondition for “compute as power” to spread rather than concentrate.
- Demand side: Agents turn compute from “ask once in a while” into “hold capacity for hours and fire tools in loops”—total spend = unit price × volume, and volume can grow faster than linearly.
- System side: τ mainly improves “how much math the silicon can do”; memory and communication walls need unified buses (e.g. Lingqu) and mature software—or you get “faster chips, still idle.”
Below we walk: why agents are compute-hungry → why total spend can rise when unit prices fall (Jevons) → memory and communication walls → how Lingqu pursues imperceptible latency → how this lands for macOS teams on cloud Macs plus harnesses.
1. Why modern AI agents are “compute hungry”
Classic Copilot-style completion is essentially one-shot inference: you provide context, the model returns a chunk of code. Claude Code, Codex CLI, and Cursor Agent turn the loop into a long-lived workload: plan → read files → run commands → observe → replan—often for dozens of rounds, each time stuffing an ever-larger context into the window.
| Dimension | Traditional completion / chat | Coding agents (Claude Code class) |
|---|---|---|
| Call pattern | Single Q&A | plan → tool → re-reason (loop) |
| Context | Current file or short snippet | Repo search + memory + terminal logs |
| Failure handling | Rewrite a line | Replay whole pipelines—tokens multiply |
| Duration | Seconds | Minutes to hours (CI hooks, long tasks) |
| Harness role | — | Cuts wasted rounds—but each round still computes |
Agents therefore push demand from “burst compute” toward “always-on service plus high-frequency small requests.” That is a different shape than training a trillion-parameter model: training wants cluster FLOPS and HBM capacity; production agents also pay a tail-latency tax—you wait on model time and tool execution, RTT, and disk I/O. ECC Skills and Instincts trim fat rounds, but fifty necessary rounds still cost fifty rounds.
2. Supply vs demand: τ lowers unit price—why does the bill climb?
If τ’s cost curve holds, the same dollar should buy more inference over time. The tension is on the demand curve, which for agents looks super-linear:
- Cheaper models embolden teams to hand agents whole-repo refactors and full test matrices;
- Mature harnesses encourage 7×24 jobs—think OpenHuman auto-fetch and OpenClaw CI triggers;
- Wider context windows inflate both input and output tokens per session.
“Compute is power” is less sloganeering than invoice structure: whoever can afford sustained GPU/NPU/API occupancy pushes automation to a granularity competitors cannot match. τ may cut per-token price without cutting how many tokens each engineer dares burn per day—and total spend sets new highs.
3. Memory wall and communication wall: you pay for waiting, not only chips
In training and inference clusters, bottlenecks are rarely “peak FLOPS on one card” alone. Two walls show up repeatedly in papers and vendor decks:
3.1 Memory wall
Accelerator arithmetic has historically outpaced memory bandwidth and capacity. GPUs and NPUs wait on data—weights, activations, KV cache moving across HBM, host memory, and remote nodes. Model FLOPS utilization (MFU) stalls; purchased FLOPS idle. For inference, long-context KV cache eats VRAM, squeezing batch size and concurrency—memory tightens before raw math does.
3.2 Communication wall
Multi-GPU training lives on gradient sync, tensor parallel, and MoE routing across intra- and inter-node links. The usual stack:
- PCIe between CPU and accelerators—finite bandwidth, copy-heavy semantics;
- NVLink / intra-node fabrics—strong inside a box, weaker once you cross machines with software still treating devices separately;
- Ethernet / InfiniBand clusters—great scale, but AllReduce and friends can consume a large fraction of a training step at scale (often cited around ~30% depending on topology and model—your mileage varies).
For coding agents, the communication wall has another face: model in a cloud API, tools on a laptop or remote runner—every run_terminal_cmd and repo read adds RTT × call count. Different layer than NVLink, same “latency tax.” Harnesses cannot repeal physics.
[App] Agent / Harness (ECC) → fewer useless rounds
[System] Unified bus / memory → fewer copies, less sync wait
[Silicon] τ-era transistor density → more math per watt
↓ multiply all three for “felt cost”
4. Lingqu and “imperceptible latency”: where τ meets the system stack
If τ answers “how cheaply can we stack compute on silicon,” Lingqu (灵衢) / unified bus architectures answer “how does software use that stack as one machine?” Public narratives (verify against current vendor whitepapers) emphasize:
- Unified memory semantics—CPU, NPU, accelerators, and memory pools closer to a single address space, fewer explicit copies and pin/unpin dances;
- Pooling and sharing—memory and compute carved per job, raising fleet-level utilization;
- Imperceptible latency as a design goal—not zero physics, but sync and stall times low enough that pipelines hide them from product teams.
For frontier model training, the multiplier matters: nominal cluster FLOPS × higher utilization → lower dollars per training run—τ on the die, Lingqu on the fabric.
For agent production, you rarely buy a cluster—you buy APIs backed by that infrastructure. Cheaper, steadier inference at scale is how industry cost curves become your per-million-token price—before Jevons pushes usage back up.
5. If compute and fabric both cheapen, what breaks out next?
When tokens get cheaper and clusters idle less, the first wave is rarely “no agents”—it is agents that stay on, parallelize harder, and specialize:
| Shape | Why it works | Bridge from today |
|---|---|---|
| 7×24 resident agents / digital staff | Marginal cost low enough to always run | Cloud Mac, OpenHuman Memory Tree |
| Multi-agent orchestration | Cheaper comms justify “many roles in a room” | ECC Skills combos, OpenClaw workers |
| Small local + large cloud models | High-frequency cheap path, rare hard path | Laptop + cloud Mac mini split |
| Agents inside CI/CD | Every commit gets review/test generation | Self-hosted macOS runners, webhooks |
The next surge may not be “one bigger model,” but compute consumed like utilities—harnesses decide how to spend wisely; buses and τ curves decide whether the spend is economically sane.
6. Closing angle: Apple Silicon, cloud Macs, and the agent invoice
Most Nuvcloud readers ship macOS / Xcode / always-on agents, not train GPU megaclusters. Two takeaways still land:
- Unified memory exists on the desktop. Apple Silicon co-packages CPU, GPU, Neural Engine, and RAM— a “small unified memory architecture” that explains why a Mac mini can feel surprisingly capable for certain on-device inference and media/agent side tasks per watt.
- Agent invoice = API/tokens + machine time + interruption cost. Running Claude Code, ECC, and OpenClaw on a always-on cloud Mac mini buys stable compute, fixed egress, and expandable disk—avoiding laptop sleep and home-ISP jitter that trigger expensive replays.
Practical homework: run the same agent task locally and on cloud for one day; log total tokens, wall time, and retry count; compare against Mac mini pricing for TCO. Harness (ECC) reduces detours; cloud Mac reduces interruptions—industry τ and Lingqu lower the curves underneath; together they define who can afford agent-era “compute power.”
Agents need to stay online: dedicated cloud Mac mini for compute and latency
Industry curves talk about τ and unified buses; your team needs machines that run agents 7×24. Nuvcloud M4 Mac mini gives bare-metal macOS, SSH/VNC, multi-region nodes, and daily/weekly/monthly billing—pair with ECC and OpenClaw so uptime and compute stay under your control.
Run a real agent workload on a day rental and compare token and wall-clock bills—view Nuvcloud plans.