Des modèles moins chers ne rendent pas automatiquement les agents moins chers. Hier, nous avons décortiqué ECC (Everything Claude Code) : un harness qui aide Claude Code et les agents Cursor à rester dans le cadre, limiter les dérives et mémoriser les contraintes entre sessions. Le harness gère l’exécution—chaque tour d’inférence, chaque tool call et chaque contexte qui grossit consomment quand même du compute et du temps.
Aujourd’hui, on descend d’un étage : qu’est-ce que τ, et pourquoi la facture agent vous concerne-t-elle ? Avec cette base, l’appétit compute des agents, l’effet Jevons, les murs mémoire/communication et Lingqu forment un seul récit.
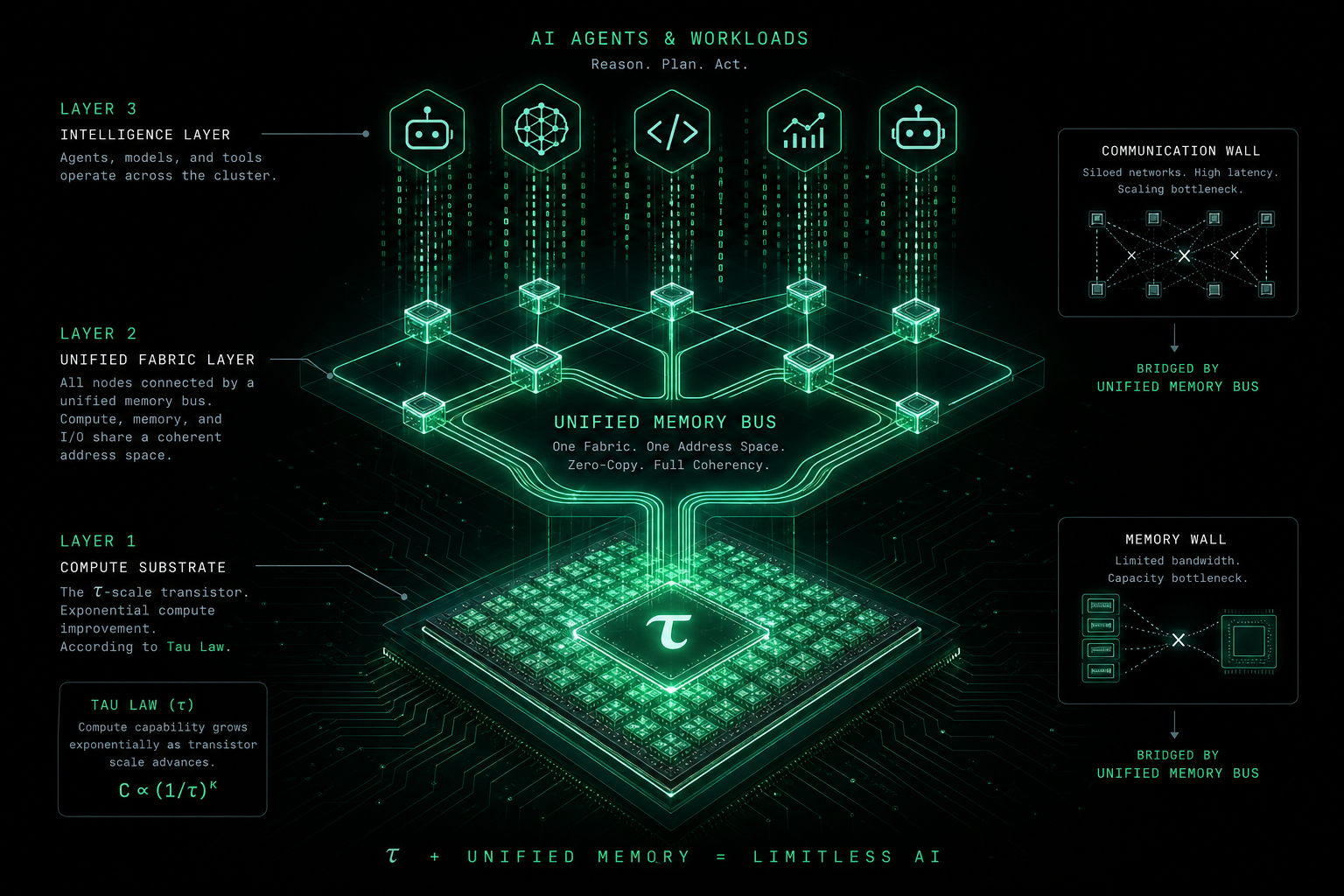
D’abord τ : qu’entend-on par « loi τ » ?
Dans le débat infra IA récent, τ (tau) apparaît souvent avec 韬 (tāo)—la loi 韬 (τ). Pour le contexte officiel sur le τ Scaling, voir la communication Huawei à l’IEEE ISCAS 2026 (offre de compute IA durable, uniformité système). Ce n’est pas une équation de manuel ni un slogan interchangeable avec la loi de Moore. C’est plutôt une tendance long terme côté offre, en trois idées :
- Les transistors (ou unités de compute équivalentes) continuent de se densifier et de bonifier. Progrès de gravure et d’empilement : plus de compute effectif par euro dans le temps.
- La densité vise l’homogénéité et le scale-out—compute, mémoire et fabric poolables pour les grands parcs IA.
- La compétition passe de « a-t-on des accélérateurs ? » à « tournent-ils vraiment ? » Les FLOPS nominales montent ; si la bande passante mémoire et le fabric traînent, l’expérience reste lente et chère.
La loi de Moore raconte surtout l’intégration qui monte. Le récit τ insiste sur une offre de compute IA durable et plus uniforme : combien de tokens effectifs un euro achète-t-il, et soutient-il des charges continues et gourmandes en bande passante (agents, entraînement) ? Le lien Huawei ci-dessus centre sur le τ Scaling ; cet article prolonge ce cadre pour les agents, sans remplacer les définitions officielles des fournisseurs.
| Angle | Moore (classique) | Loi 韬 (τ) (récit industrie) |
|---|---|---|
| Focus | Transistors sur la puce | Coût unitaire et scale-out IA |
| Question type | « Prochaine gravure ? » | « Plus de tokens / cluster plus gros, même budget ? » |
| Agents | Indirect | Direct—prix API ↓, usage ↑ plus vite |
| Non résolu seul | Murs mémoire, fabric, SW | Besoin d’interco type Lingqu |
Pour les praticiens, la conclusion utile sur τ—sans formule :
- Offre : à long terme, un dollar achète tendanciellement plus de compute—préalable à une « puissance compute » qui se diffuse.
- Demande : les agents passent du ponctuel au « occupation longue + boucles d’outils »—coût = prix × volume, volume parfois superlinéaire.
- Système : τ améliore le silicium ; murs mémoire et communication demandent bus unifié (Lingqu) et stack mûre—sinon « puces plus rapides, toujours à l’arrêt ».
Ordre de lecture : appétit compute des agents → Jevons quand le prix unitaire baisse → murs mémoire et communication → Lingqu et latence imperceptible → Mac cloud et harness pour les équipes macOS.
1. Pourquoi les agents modernes « mangent » du compute
L’autocomplétion type Copilot, c’est une inférence ponctuelle : contexte → extrait de code. Claude Code, Codex CLI, Cursor Agent deviennent une charge longue : plan → fichiers → shell → observation → replan—souvent des dizaines de tours, contexte qui gonfle à chaque fois.
| Dimension | Chat / completion | Agents de code |
|---|---|---|
| Forme | Q/R unique | plan → tool → boucle |
| Contexte | Fichier court | Repo + mémoire + logs |
| Échec | Religne | Rejoue le pipeline—tokens ×N |
| Durée | Secondes | Minutes à heures (CI, longues tâches) |
| Harness | — | Moins de tours inutiles—chaque tour compte |
La demande devient « service permanent + petites requêtes fréquentes ». Ce n’est pas la même forme qu’entraîner un modèle trillion : l’entraînement veut des FLOPS de cluster ; les agents en prod paient aussi la latence de queue—modèle, outils, RTT, disque. ECC élimine du gras, pas les cinquante tours nécessaires.
2. τ baisse le prix unitaire—pourquoi la note monte ?
Si la courbe de coût τ tient la route, le même euro devrait acheter plus d’inférence dans le temps. La tension est côté demande, superlinéaire pour les agents :
- Modèles moins chers → refactors repo entier, matrices de tests ;
- Harness matures → jobs 7×24 (OpenHuman, OpenClaw) ;
- Fenêtres larges → tokens entrée/sortie gonflés.
« Le compute est un pouvoir » décrit surtout la structure de facture : qui peut payer une occupation GPU/NPU/API durable pousse l’automatisation plus finement que la concurrence. τ peut baisser le prix par token sans baisser combien de tokens chaque ingénieur ose brûler par jour—et le total peut repartir vers des records.
3. Murs mémoire et communication : on paie aussi l’attente
Dans les clusters d’entraînement et d’inférence, le goulot n’est plus seulement le pic FLOPS d’une carte. Deux « murs » reviennent dans la littérature et les decks fournisseurs :
3.1 Mur mémoire
L’arithmétique des accélérateurs a longtemps dépassé la bande passante et la capacité mémoire. GPU/NPU attendent les données—poids, activations, KV cache entre HBM, RAM hôte et nœuds distants. MFU bas : FLOPS achetés à l’arrêt. En inférence, un KV cache long contexte sature la VRAM—la mémoire se tend avant le calcul brut.
3.2 Mur communication
L’entraînement multi-GPU repose sur sync de gradients, parallélisme tensoriel, MoE—liens intra- et inter-nœuds. Pile habituelle :
- PCIe CPU↔accélérateurs—bande passante et sémantique de copie limitées ;
- NVLink / fabric intra-boîtier—fort en local, plus faible une fois la machine franchie ;
- Ethernet / InfiniBand—bon scale-out, mais AllReduce peut peser lourd sur un step (souvent ~30 % selon topo—variable).
Pour les agents de code, autre visage : modèle en API cloud, outils sur laptop ou runner distant—chaque run_terminal_cmd et lecture repo ajoute RTT × appels. Couche différente de NVLink, même « taxe de latence ». Le harness ne supprime pas la physique.
[App] Agent / Harness (ECC)
[Système] Bus unifié / mémoire
[Silicium] Densité τ
↓ coût ressenti = produit
4. Lingqu (灵衢) et latence « imperceptible »
Si τ répond « combien de compute empiler bon marché sur le silicium », Lingqu (灵衢) / bus unifié répond « comment le logiciel utilise la pile comme une machine ». Récits publics (vérifier les whitepapers actuels) :
- Sémantique mémoire unifiée—CPU, NPU, accélérateurs, pools plus proches d’un espace d’adresses, moins de copies explicites ;
- Poolage et partage—mémoire et compute découpés par tâche, meilleure utilisation flotte ;
- Latence imperceptible—pas zéro physique, mais sync masquée par le pipeline.
Pour l’entraînement flagship : FLOPS nominals × meilleure utilisation → moins de dollars par run—τ sur le die, Lingqu sur le fabric, en multiplicateur.
Pour la prod agent, vous achetez rarement un cluster—vous achetez des API adossées à cette infra. Inférence moins chère et plus stable devient votre prix au million de tokens—avant que Jevons ne remonte la demande.
5. Si compute et fabric baissent, quoi ensuite ?
Quand les tokens baissent et que les clusters tournent moins à vide, la première vague n’est pas « plus d’agents » mais des agents toujours allumés, plus parallèles, plus spécialisés :
| Forme | Pourquoi | Lien |
|---|---|---|
| Agents 7×24 | Coût marginal bas | Mac cloud, OpenHuman |
| Multi-agents | Comms abordables | ECC, OpenClaw |
| Petit local + gros cloud | Fréquent vs rare | Portable + Mac mini |
| Agents en CI/CD | Chaque commit | Runners macOS |
La prochaine vague n’est peut-être pas « un modèle plus gros », mais du compute consommé comme une utilité—le harness décide comment dépenser ; bus et courbe τ si c’est rationnel.
6. Apple Silicon, Mac cloud, facture agent
La plupart des lecteurs Nuvcloud livrent macOS / Xcode / agents permanents, pas des mégaclusters GPU. Deux points utiles :
- Mémoire unifiée sur le bureau. Apple Silicon : CPU, GPU, Neural Engine, RAM—petite archi unifiée ; Mac mini efficace pour certaines tâches agent/inference au watt.
- Facture = API + machine + interruptions. ECC/OpenClaw sur Mac mini cloud toujours allumé : compute stable, IP fixe, disque—moins de replays coûteux (sommeil laptop, FAI instable).
Exercice : même tâche agent local vs cloud une journée ; journal tokens, temps, retries ; comparer aux tarifs Mac mini (TCO). Harness (ECC) = moins de détours ; Mac cloud = moins d’interruptions ; τ et Lingqu abaissent les courbes industrielles—ensemble, qui peut se payer la « puissance compute » de l’ère agent.
Agents toujours en ligne : Mac mini cloud dédié pour compute et latence
Les courbes τ concernent l'industrie ; vous avez besoin de machines 7×24 pour les agents. Nuvcloud M4 Mac mini : macOS bare metal, SSH/VNC, multi-régions, facturation jour/semaine/mois—avec ECC et OpenClaw.
Testez un vrai workload agent à la journée—voir les offres Nuvcloud.