モデル単価が下がっても、Agent の請求が自動的に下がるわけではありません。前回は ECC(Everything Claude Code) を Harness 層として整理しました。Claude Code や Cursor Agent が複雑な工程で迷子になりにくく、権限を越えにくく、セッションをまたいで制約を覚えられるのは Harness の仕事です。ただし「どう動くか」を整えても、推論の各ラウンド、ツール呼び出し、膨らむコンテキストには、いずれも算力と時間がかかります。
今回は視点を一段下げ、前提から扱います。τ(タウ)とは何か、なぜ Agent 運用者の請求とつながるのか。ここが腹落ちすると、Agent が算力を「食う」理由、単価低下でも総額が増えるジェボンズ的な話、メモリ壁・通信壁、そして霊衢(Lingqu)が目指す「無感遅延」が一本の線で読めます。
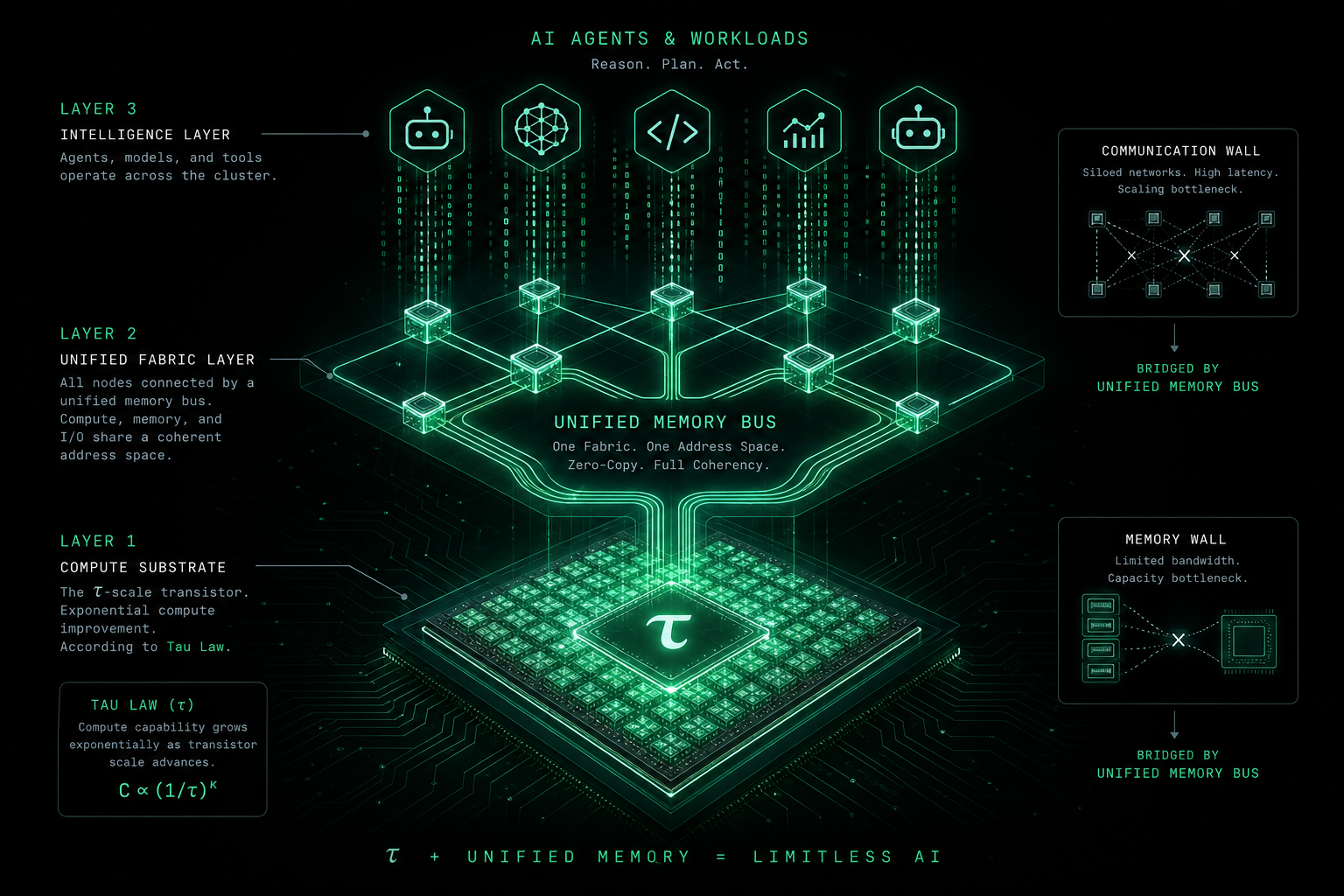
まず τ:韬(τ)法則とは何か
近年の AI インフラ議論では、ギリシャ文字の τ(タウ)が中国語の「韬(タオ)」と並んで語られることがあります——韬(τ)法則と呼ばれる枠組みです。これは教科書に載った物理式ではなく、モアの法則の言い換えでもありません。産業界が長期の供給側トレンドを短くまとめたナラティブに近く、大意は次の三つに分けられます。
- トランジスタ(または等価な演算単位)は、より多く・密に・安くなる。プロセスとパッケージの進化が、面積あたりの実効算力コストを長期で押し下げる。
- 密度は「より均一で、よりスケールアウトしやすい」方向へ。ピーク FLOPS だけでなく、大規模 AI クラスタで compute・メモリ・インタコネクトをプールしやすい形が求められる。
- 競争の焦点は「カードがあるか」から「カードが実際に働いているか」へ。公称 FLOPS は上がっても、メモリ帯域や機間通信が追いつかなければ、体感は遅く高いまま。
モアの法則(おおよそ 18〜24 か月でトランジスタ数が倍増、という古典的ストーリー)は、時間とともに集積度が上がる話です。一方、公開ホワイトペーパーで語られる韬(τ)法則は、AI 向け算力供給の持続可能性と均質化を強調します。同じ予算で有効な学習・推論トークンをどれだけ回せるか。Agent や大規模学習のような常時稼働・高帯域負荷を支えられるか。ベンダーによっては τ をコスト曲線の傾きそのものと呼ぶこともありますが、本稿では特定企業の独自定義には結びつけず、業界で通じる通俗的な意味で使います。
| 比較軸 | モアの法則(古典) | 韬(τ)法則(産業ナラティブ) |
|---|---|---|
| 注目点 | チップ上のトランジスタ数 | AI 文脈の単位算力コストとシステム拡張性 |
| 典型的な問い | 「次世代プロセスはいつ量産か」 | 「同じ予算で、もっとトークン/大きなクラスタが回るか」 |
| Agent への意味 | 間接的——推論チップは強くなる | 直接的——API 単価は下がりうるが、使用量が先に伸びる |
| 単独では解かない | メモリ壁、通信壁、ソフト利用率 | 霊衢(Lingqu)などの統一インタコネクトが要る |
開発者が覚えるべき実務上の結論は、式を暗記しなくてよい、ということです。
- 供給側: 長期では同じドル(円)で買える算力・トークン枠は増えがち——「算力=権力」が分散しうる前提。
- 需要側: Agent は算力需要を「たまに聞く」から「長時間占有+多段ツール」へ。総額=単価×使用量で、使用量は非線形に膨らみうる。
- システム側: τ は主に「シリコン上でいくら計算できるか」。メモリ壁・通信壁は統一バス(霊衢)とソフトスタック——さもないと「チップは速いのに利用率が低い」空転が残る。
以降の順序:Agent が算力を食う理由 → τ で単価が下がっても総額が上がる仕組み(ジェボンズ)→ メモリ壁・通信壁 → 霊衢と無感遅延 → クラウド Mac と Harness の分担。
1. 現代の AI Agent はなぜ算力に「貪欲」か
従来の Copilot 型補完は、本質的に一回限りの推論です。Claude Code、Codex CLI、Cursor Agent は、計画→ファイル読取→コマンド実行→結果確認→再計画という長時間占有型ループに変えます。ラウンドごとにコンテキストが膨らみ、毎回ウィンドウに押し込まれます。
| 軸 | 従来の補完/チャット | コーディング Agent(Claude Code 級) |
|---|---|---|
| 呼び出し形態 | 単発 Q&A | plan → tool → 再推論(ループ) |
| コンテキスト | 現在ファイルや短い断片 | リポジトリ検索+メモリ+端末ログ |
| 失敗・再試行 | 一行書き直し | パイプライン全体の再実行——トークン倍増 |
| 実行時間 | 秒級 | 分〜時間(CI 連携、長タスク) |
| Harness | — | 無駄ラウンド削減——各ラウンドは依然として計算する |
需要の形は「ピークで一瞬」から「常駐サービス+高頻度の小リクエスト」へ。大規模学習とは違い、本番 Agent はテール遅延も払う——モデル思考時間に加え、ツール実行、ネットワーク RTT、ディスク I/O。ECC の Skills/Instincts は無駄を削るが、必要な 50 ラウンドのコストは 50 ラウンド分残る。
2. 供給と需要:τ が単価を下げても、なぜ請求は上がるか
τ が描くコスト曲線が成り立つなら、長期では同じドルで買える推論算力は増えるはずです。矛盾は需要関数——Agent は超線形に近い。
- モデルが安いほど、チームは「リポジトリ全体のリファクタ」「フルテストマトリクス」を Agent に任せやすい;
- Harness が成熟すると、OpenHuman の auto-fetch や OpenClaw の CI トリガーのように 7×24 常駐を敢えて回す;
- コンテキストウィンドウ拡大で、入力・出力トークンが同時に膨らむ。
「算力=権力」はスローガンではなく請求の構造です。GPU/NPU/API 枠を長期で払える者ほど、競合が踏み込めない粒度まで自動化を押せます。τ が「トークン単価」だけを下げ、「エンジニア一人あたり一日に燃やすトークン量」を下げないなら、総支出は再びピークを更新し得ます。
3. メモリ壁と通信壁:高いのはチップだけではない
学習・推論クラスタでは、ボトルネックはもはや「1枚のピーク FLOPS」だけではありません。論文とベンダーデックに繰り返し現れる「二つの壁」:
3.1 メモリ壁(Memory Wall)
加速器の演算能力の伸びは、長期的にメモリ帯域・容量の伸びを上回りがちです。GPU/NPU はデータ待ち——重み、活性化、KV キャッシュが HBM・ホストメモリ・ノード間を移動。MFU(モデル FLOPS 利用率)が上がらず、買った FLOPS の一部が空転。推論では長コンテキスト KV が VRAM を食い、バッチと並列が絞られる——「算力よりメモリが先に詰まる」。
3.2 通信壁(Communication Wall)
マルチ GPU 学習では勾配同期、テンソル並列、MoE が機内・機間リンクに依存します。
- PCIe: CPU と加速器の間——帯域・遅延・コピー语义がボトルネックになりやすい;
- NVLink 等: 同一筐体内は良好でも、跨ぎは上位ネットワーク、ソフトは依然「複数デバイス」;
- Ethernet/InfiniBand: 拡張性は高いが AllReduce 等がステップの大きな割合を占めうる(トポロジとモデル次第で三成前後とされることも——環境依存)。
コーディング Agent には別の顔もある。ノートで Agent、モデルはクラウド API、ツールはローカルまたはリモート Runner——run_terminal_cmd やリポジトリ読取のたびに RTT × 回数。NVLink とは層が違うが、同じ「遅延税」。
[アプリ] Agent / Harness(ECC) → 無駄ラウンド削減
[システム] 統一バス/メモリ语义 → コピー・同期待ち削減
[チップ] τ 曲線下のトランジスタ密度 → ワットあたり演算増
↓ 三つを掛け合わせて「体感コスト」
4. 霊衢(Lingqu)と「無感遅延」:τ 法則はシステム層でどう効くか
τ が「シリコン上にいかに安く算力を積めるか」に答えるなら、霊衢/統一バス(Unified Bus) は「積んだ算力を一つのマシンのように使えるか」に答えます。公開材料の中心叙事(数値はベンダー最新版で確認):
- 統一メモリ语义: CPU、NPU、加速器、メモリプールがアドレス空間に近づき、明示コピー・pin/unpin が減る;
- プールと共有: タスク単位でメモリ・算力を切り出し、クラスタ利用率を上げる;
- 無感遅延の目標: 物理ゼロではなく、同期・待ちをパイプラインが隠蔽し、業務が感知しない程度まで下げる。
フラッグシップモデルの学習では、公称 FLOPS × 利用率の積が効く——τ(チップ)と霊衢(インタコネクト)は乗算で、代替ではない。
Agent 本番ではクラスタを買わず API を買う。背後のインフラが効率化すれば API 単価に下振れ余地——その後ジェボンズが需要を押し戻す。
5. 算力とインタコネクトが両方下がったら、次に何が噴くか
トークンが安くなりクラスタの空転が減るとき、最初の波は「エージェント不要」ではなく、常時オン・より並列・より専門化した Agentです:
| 形態 | 成立理由 | 今日との接続 |
|---|---|---|
| 7×24 常駐 Agent/デジタル従業員 | 限界費用が十分低い | クラウド Mac、OpenHuman Memory Tree |
| マルチ Agent 編成 | 通信・推論が安いと「多役割会議」が成立 | ECC Skills、OpenClaw ワーカー |
| 小型ローカル+大型クラウド | 高頻度は下げ、難問は上げ | ノート+クラウド Mac mini |
| CI/CD 深埋め Agent | コミットごとにレビュー・テスト生成 | 自前 macOS Runner、Webhook |
次の波は「もっと巨大な単一モデル」だけではなく、水道光熱のように常時消費される算力の応用層かもしれない——Harness が賢く使う方法を決め、バスと τ 曲線が経済性を決める。
6. まとめ:Apple Silicon、クラウド Mac、Agent 請求
Nuvcloud の読者の多くは GPU 学習クラスタより、macOS/Xcode/常駐 Agentです。それでも二点は持ち帰れます。
- 単機にも「統一メモリ」の恩恵がある。 Apple Silicon は CPU、GPU、Neural Engine、RAM を同一パッケージに——ローカル推論や中規模モデル、一部 Agent 補助タスクで Mac mini が「ワットあたり十分」に感じられる理由の一端。
- Agent 請求= API/トークン+マシン時間+中断コスト。 Claude Code、ECC、OpenClaw を常時オンラインのクラウド Mac miniに載せるのは、安定算力・固定出口 IP・拡張ディスクを買うこと——ノート閉蓋や家庭回線の揺れで長タスクが落ち、再実行が月額より高くつくことがある。
実務:同一 Agent タスクをローカルとクラウドで一日ずつ走らせ、総トークン・壁時計時間・再試行回数を記録し、Mac mini 料金と TCO 比較。Harness(ECC)は遠回りを減らし、クラウド Mac は中断を減らす——業界の τ と霊衢が曲線を下げ、三者の積が Agent 時代の「算力の配分」になる。
Agentを常時稼働:専用クラウド Mac mini で算力と遅延を確保
τ曲線と統一バスは業界の話—現場では7×24でAgentを回すマシンが要る。Nuvcloud M4 Mac miniはベアメタル macOS、SSH/VNC、多リージョン、日/週/月課金—ECC・OpenClawと組み合わせ可能。
本番に近いAgentタスクを日額で試算—Nuvcloudプランを見る。