모델 단가가 내려가도 Agent 청구서가 자동으로 가벼워지지는 않습니다. 지난 글에서는 ECC(Everything Claude Code) 같은 Harness를 다뤘습니다. Claude Code·Cursor Agent가 복잡한 엔지니어링 작업에서 덜 헤매고, 권한을 넘지 않으며, 세션을 넘어 제약을 기억하게 만드는 층입니다. Harness는 «어떻게 일할지»를 다루지만, 매 추론 라운드·도구 호출·불어나는 컨텍스트마다 여전히 연산과 시간이 듭니다.
이번에는 한 단계 아래로 내려가 선행 질문부터 짚습니다. τ(타우)가 무엇이고, Agent 청구와 무슨 관계인가. 이 그림이 잡히면 Agent가 연산을 «탐식»하는 이유, 단가 하락에도 총액이 오를 수 있는 제비스(Jevons) 논리, 메모리·통신 벽, 灵衢(Lingqu)가 노리는 «무감 지연»이 한 줄기로 읽힙니다.
먼저 τ: 韬(τ) 법칙이란 무엇인가
최근 AI 인프라 담론에서 그리스 문자 τ(타우)는 중국어 「韬(타오)」와 함께 거론되곤 합니다—韬(τ) 법칙이라 부르는 틀입니다. 이것은 교과서의 물리 공식이 아니며, 무어의 법칙을 한 문장으로 대체하는 슬로건도 아닙니다. 산업계가 장기 공급 측 추세를 요약한 내러티브에 가깝고, 핵심은 대개 세 가지입니다.
- 트랜지스터(또는 등가 연산 단위)는 더 많이, 더 촘촘히, 더 싸게 간다. 공정·패키징 진화가 단위 면적당 실효 연산 비용을 장기적으로 누른다.
- 밀도는 «더 균일하고 확장 가능»한 방향으로. 피크 FLOPS만이 아니라 대규모 AI 클러스터에서 연산·메모리·인터커넥트를 풀링하기 쉬운 형태.
- 경쟁 초점은 «카드가 있느냐»에서 «카드가 실제로 일하느냐»로. 공칭 FLOPS는 오르는데 메모리 대역·기간 통신이 뒤처지면 체감은 여전히 느리고 비싸다.
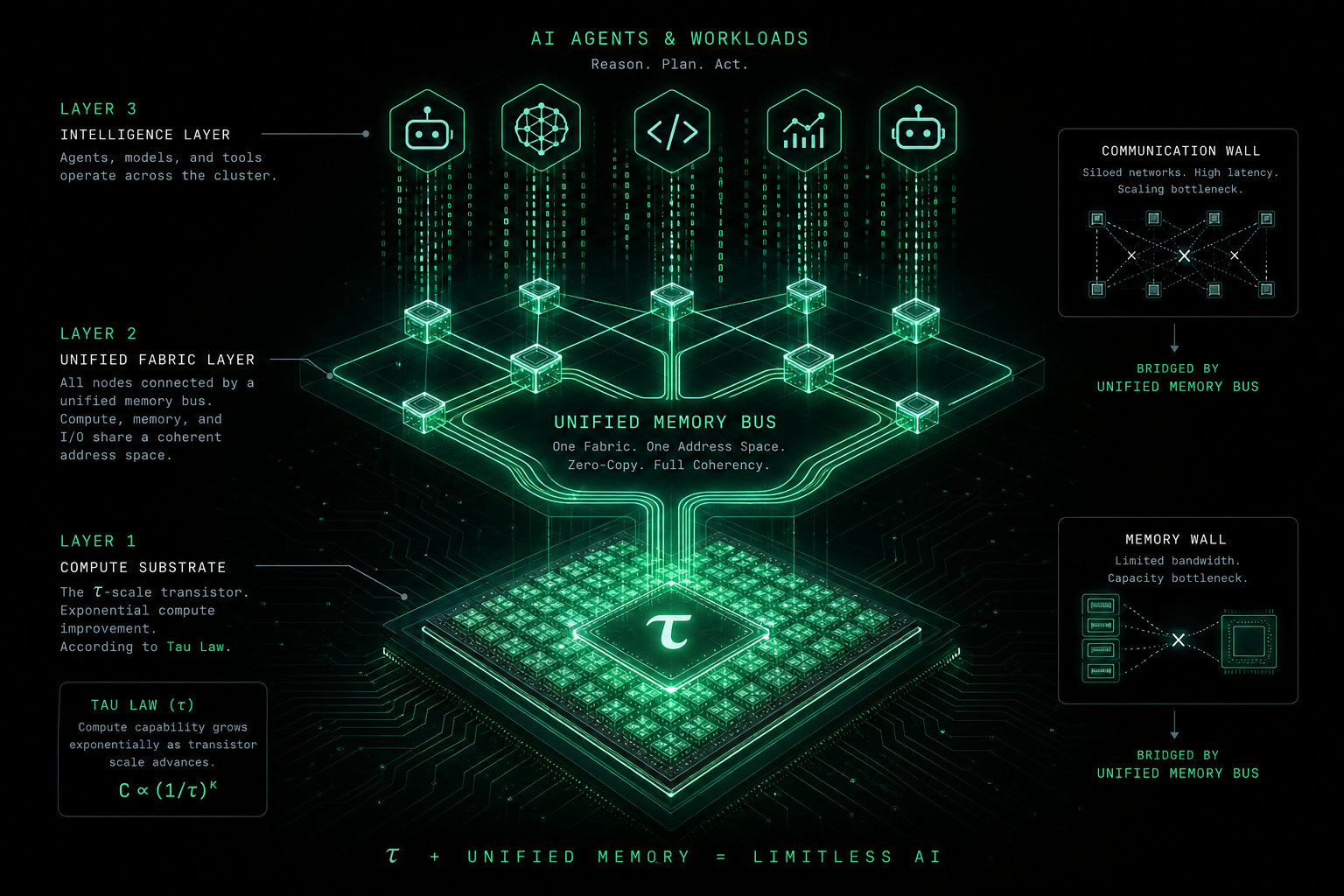
무어의 법칙(대략 18~24개월마다 트랜지스터 수 배가)은 시간에 따른 집적도 상승 이야기입니다. 공개 백서의 韬(τ) 법칙은 AI 연산 공급의 지속 가능성과 균질화를 강조합니다. 같은 예산으로 유효한 학습·추론 토큰을 얼마나 돌릴 수 있는지, Agent·대규모 학습 같은 상시·고대역 부하를 받쳐 줄 수 있는지. 벤더마다 τ를 비용 곡선의 기울기로 부르기도 하나, 본문은 특정 회사 독점 정의가 아닌 업계 통용 의미를 씁니다.
| 비교 | 무어의 법칙(고전) | 韬(τ) 법칙(산업 내러티브) |
|---|---|---|
| 초점 | 다이 위 트랜지스터 수 | AI 맥락의 단위 연산 비용·시스템 확장성 |
| 전형적 질문 | «다음 공정 언제 양산?» | «같은 예산으로 더 많은 토큰·더 큰 클러스터?» |
| Agent 함의 | 간접—추론 칩은 강해짐 | 직접—API 단가는 내릴 수 있으나 사용량이 더 빨리 늘 수 있음 |
| 단독으로 못 푸는 것 | 메모리 벽, 통신 벽, SW 활용률 | 灵衢(Lingqu)류 통합 버스 필요 |
실무자가 기억할 실용 결론—공식 암기 불필요:
- 공급: 장기적으로 같은 달러(원)가 살 연산·토큰 할당량은 늘기 쉽다—«연산=권력»이 분산될 전제.
- 수요: Agent는 «가끔 물어보기»에서 «장시간 점유+다단 도구»로—총액=단가×사용량, 사용량은 비선형 팽창.
- 시스템: τ는 주로 «실리콘에서 얼마나 계산하나»—메모리·통신 벽은 통합 버스(灵衢)와 스택, 아니면 «칩은 빠른데 활용률 낮음» 공회전.
이후 순서: Agent 연산 «탐식» → 단가 하락에도 총액 상승(제비스) → 메모리·통신 벽 → 灵衢와 무감 지연 → 클라우드 Mac과 Harness 분담.
1. 현대 AI Agent가 연산에 «탐욕적»인 이유
전통 Copilot식 완성은 본질적으로 일회성 추론입니다. Claude Code, Codex CLI, Cursor Agent는 계획→파일 읽기→명령 실행→결과 확인→재계획의 장시간 점유형 루프로 바꿉니다. 라운드마다 컨텍스트가 부풀어 매번 윈도에 밀어 넣습니다.
| 축 | 기존 완성/채팅 | 코딩 Agent(Claude Code급) |
|---|---|---|
| 호출 형태 | 단발 Q&A | plan → tool → 재추론(루프) |
| 컨텍스트 | 현재 파일·짧은 조각 | 저장소 검색+메모리+터미널 로그 |
| 실패·재시도 | 한 줄 수정 | 파이프라인 전체 재실행—토큰 배가 |
| 실행 시간 | 초 단위 | 분~시간(CI 연동) |
| Harness | — | 낭비 라운드 감소—라운드마다 여전히 연산 |
수요 형태는 «피크로 잠깐»에서 «상주 서비스+고빈도 소요청»으로. 대규모 학습과 달리 프로덕션 Agent는 꼬리 지연도 낸다—모델 시간+도구+RTT+디스크. ECC Skills/Instincts는 낭비를 깎지만 필요한 50라운드 비용은 50라운드.
2. 공급과 수요: τ가 단가를 깎아도 청구가 오르는 이유
τ 곡선이 성립하면 장기적으로 같은 달러의 추론 연산은 늘어야 합니다. 긴장은 수요 함수—Agent는 초선형에 가깝습니다.
- 모델이 싸질수록 저장소 전체 리팩터·풀 테스트 매트릭스를 Agent에 맡기기 쉬움;
- Harness 성숙→ OpenHuman auto-fetch, OpenClaw CI 트리거처럼 7×24 상주;
- 컨텍스트 창 확대→ 입·출력 토큰 동시 팽창.
«연산=권력»은 슬로건이 아니라 청구 구조입니다. GPU/NPU/API 할당을 장기로 감당하는 쪽이 경쟁이 못 가는 세밀도까지 자동화를 밀 수 있습니다. τ가 토큰 단가만 내리고 «엔지니어 하루 소모 토큰»을 내리지 않으면 총지출은 다시 고점을 찍을 수 있습니다.
3. 메모리 벽과 통신 벽: 비싼 것은 칩만이 아니다
학습·추론 클러스터에서 병목은 더 이상 «한 장의 피크 FLOPS»만이 아닙니다. 문헌과 백서에 반복되는 «두 벽»:
3.1 메모리 벽
가속기 연산 성장은 메모리 대역·용량 성장을 장기적으로 앞선다. GPU/NPU는 데이터 대기—가중치·활성·KV 캐시가 HBM·호스트·노드 간 이동. MFU가 못 올라가면 산 FLOPS가 공회전. 추론에서 장문맥 KV가 VRAM을 먹어 배치·동시성이 줄어든다.
3.2 통신 벽
멀티 GPU 학습은 그래디언트 동기화, 텐서 병렬, MoE—노드 내·간 링크에 의존합니다. 일반적 스택:
- PCIe CPU↔가속기—대역·지연·복사 의미가 병목;
- NVLink 등—동일 섀시 내는 양호, 머신 경계 넘으면 약화;
- Ethernet/InfiniBand—확장성은 높으나 AllReduce가 스텝의 큰 비중(~30% 언급도—환경 의존).
코딩 Agent에는 다른 얼굴: 노트북 Agent, 모델은 클라우드 API, 도구는 로컬/원격 Runner—run_terminal_cmd·저장소 읽기마다 RTT×횟수. NVLink과 층은 다르지만 같은 «지연 세금».
[앱] Agent/Harness(ECC) → 낭비 라운드 감소
[시스템] 통합 버스/메모리 → 복사·동기 대기 감소
[칩] τ 밀도 → 와트당 연산 증가
↓ 셋의 곱이 체감 비용
4. 灵衢(Lingqu)와 «무감 지연»: τ 법칙은 시스템층에서
τ가 «실리콘에 얼마나 싸게 쌓나»에 답하면, 灵衢(Lingqu)/통합 버스는 «쌓은 연산을 한 대의 기계처럼 쓰나»에 답합니다. 공개 서술(최신 백서로 확인):
- 통합 메모리 의미—CPU·NPU·가속기·풀이 주소 공간에 가깝게, 명시적 복사 감소;
- 풀링·공유—작업별로 메모리·연산 할당, 클러스터 활용률 향상;
- 무감 지연 목표—물리적 0은 아니지만 파이프라인이 가리는 동기·대기.
플래그십 학습: 공칭 FLOPS×활용률→런당 달러 하락—τ(다이)와 灵衢(패브릭)은 곱셈 관계.
Agent 프로덕션은 클러스터가 아니라 API를 삽니다. 저렴하고 안정적인 대규모 추론이 백만 토큰 단가가 되고—그다음 제비스가 수요를 밀어 올립니다.
5. 연산·인터커넥트가 둘 다 싸지면
토큰이 싸지고 클러스터가 덜 놀면 첫 파도는 «Agent 없음»이 아니라 항상 켜 두고, 더 병렬·전문화하는 Agent입니다:
| 형태 | 이유 | 연결 |
|---|---|---|
| 7×24 상주 Agent | 한계비용 충분히 낮음 | 클라우드 Mac, OpenHuman |
| 멀티 Agent 편성 | 통신·추론 저렴 | ECC, OpenClaw |
| 소형 로컬+대형 클라우드 | 고빈도 vs 난문제 | 노트북+Mac mini |
| CI/CD 내장 Agent | 커밋마다 | macOS Runner |
다음 파도는 «더 큰 단일 모델»만이 아닐 수 있습니다—수도·전기처럼 상시 소비되는 연산의 응용층. Harness가 쓰는 법, 버스와 τ 곡선이 경제성을 정합니다.
6. Apple Silicon, 클라우드 Mac, Agent 청구
Nuvcloud 독자 다수는 GPU 메가클러스터보다 macOS/Xcode/상시 Agent입니다. 두 가지:
- 단일 기기에도 통합 메모리 이점. Apple Silicon은 CPU·GPU·Neural Engine·RAM 공패키지—일부 Agent 보조·추론에서 Mac mini가 와트당 괜찮은 이유.
- 청구=API/토큰+머신 시간+중단 비용. ECC·OpenClaw를 상시 온라인 클라우드 Mac mini에—안정 연산·고정 egress·디스크. 노트북 덮개·가정용 회선 흔들림의 재실행이 월 임대보다 비쌀 수 있음.
실습: 동일 Agent 작업을 로컬·클라우드에서 하루씩, 총 토큰·벽시계·재시도 기록 후 Mac mini 요금과 TCO 비교. Harness(ECC)는 우회를 줄이고, 클라우드 Mac은 중단을 줄입니다—산업의 τ와 灵衢가 곡선을 내리고, 셋의 곱이 Agent 시대 «연산 권력»입니다.
Agent 상시 가동: 전용 클라우드 Mac mini로 연산·지연 확보
τ 곡선은 산업 이야기—팀에는 7×24 Agent 머신이 필요합니다. Nuvcloud M4 Mac mini: 베어메탈 macOS, SSH/VNC, 다지역, 일/주/월 과금—ECC·OpenClaw와 병행.
실제 Agent 워크로드를 일 단위로 검증—Nuvcloud 요금 보기.