Более дешёвые модели не делают агентов автоматически дешевле. Вчера мы разобрали ECC (Everything Claude Code) как слой harness: меньше лишних шагов, жёстче guardrails, ограничения помнятся между сессиями. Harness управляет как работать — но каждый раунд инференса, каждый tool call и растущий контекст всё равно жгут compute и время.
Сегодня спускаемся на уровень ниже: что такое τ и почему это бьёт по счёту агента? С этой базой голод агентов к compute, эффект Джевонса, стены памяти и связи и роль Lingqu складываются в одну картину.
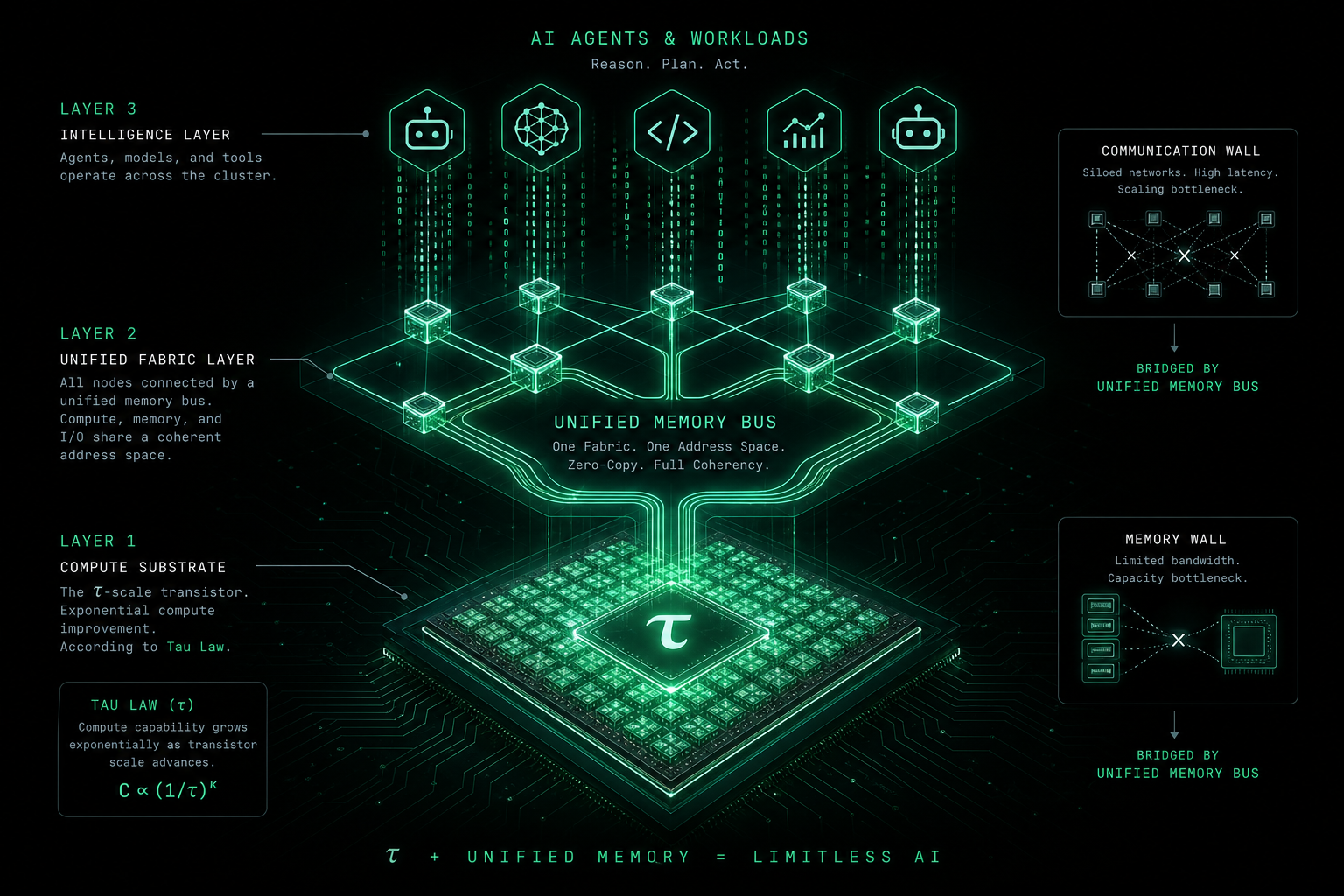
Сначала τ: что называют «законом τ»?
В дискурсе AI-инфраструктуры τ (тау) часто идёт рядом с 韬 (tāo) — закон 韬 (τ). Первичный контекст по τ Scaling — публикация Huawei на IEEE ISCAS 2026 (устойчивое предложение AI-compute, однородность системы). Это не формула из учебника физики и не однострочная замена закону Мура. Скорее отраслевая формула долгосрочного тренда предложения в трёх тезисах:
- Транзисторы (или эквивалентные вычислительные ячейки) становятся плотнее и дешевле. Процесс и упаковка давят стоимость эффективного compute.
- Плотность стремится к однородности и scale-out — compute, память и fabric как пулируемые ресурсы больших AI-кластеров.
- Фокус смещается с «есть ли ускорители» на «загружены ли они». Номинальные FLOPS растут, но при отставании bandwidth и fabric остаётся медленно и дорого.
Закон Мура — история роста интеграции во времени. Нарратив τ в материалах подчёркивает устойчивое, более однородное предложение AI-compute: сколько эффективных токенов покупает доллар и выдержит ли оно постоянные, прожорливые по bandwidth нагрузки вроде агентов. Ссылка на Huawei выше — про τ Scaling; эта статья развивает тему для агентов, не подменяя официальные определения вендоров.
| Угол | Мур (классика) | Закон 韬 (τ) |
|---|---|---|
| Фокус | Транзисторы на кристалле | Удельная стоимость compute и масштабируемость для AI |
| Вопрос | «Когда следующий техпроцесс?» | «Больше токенов / крупнее кластер за тот же бюджет?» |
| Агенты | Косвенно | Напрямую — цена API ↓, объём ↑ быстрее |
| Не решает сам | Стены памяти, fabric, ПО | Нужен unified bus вроде Lingqu |
Практический вывод по τ — без формул:
- Предложение: долгосрочно тот же доллар покупает больше compute — предпосылка «рассеивания» compute-власти.
- Спрос: агенты переводят нагрузку из «спросил раз» в «часы tool-циклов» — счёт = цена × объём, объём может расти сверхлинейно.
- Система: τ улучшает кремний; стены памяти и связи требуют Lingqu и зрелого стека — иначе «быстрые чипы, простой».
Далее: голод агентов → Джевонс при падающей цене за единицу → стены → Lingqu → облачный Mac и harness для macOS-команд.
1. Почему современные агенты «прожорливы»
Классический Copilot — один инференс: контекст → фрагмент кода. Claude Code, Codex CLI, Cursor Agent — долгая сессия: план → файлы → shell → наблюдение → replan, десятки раундов, контекст растёт каждый круг.
| Измерение | Чат / completion | Кодинг-агенты |
|---|---|---|
| Паттерн | Один Q/A | plan → tool → цикл |
| Контекст | Файл | Репо + память + логи |
| Сбой | Переписать строку | Перезапуск pipeline — токены ×N |
| Длительность | Секунды | Минуты–часы (CI) |
| Harness | — | Меньше мусорных раундов — каждый раунд считается |
Спрос становится «постоянный сервис + частые мелкие запросы». Это не тот же профиль, что обучение триллионных параметров: там FLOPS кластера; у прод-агентов ещё хвостовая задержка — модель, tools, RTT, диск. ECC убирает жир, не пятьдесят нужных раундов.
2. τ давит цену за единицу — почему растёт итог?
Если кривая τ держится, тот же доллар со временем покупает больше инференса. Напряжение на кривой спроса, для агентов близкой к сверхлинейной:
- Дешевле модели → целые рефакторы репо и полные тест-матрицы агентам;
- Зрелый harness → 24/7 (OpenHuman, OpenClaw);
- Широкие окна → раздувание input/output токенов.
«Compute — власть» — это структура счёта: кто тянет длительную занятость GPU/NPU/API, тот автоматизирует тоньше. τ может резать цену токена, не обязательно сколько токенов инженер сжигает в день — итог снова бьёт рекорды.
3. Стена памяти и стена связи: платите и за ожидание
В кластерах обучения и инференса узкое место редко только «пик FLOPS одной карты». В статьях и whitepaper’ах снова две «стены»:
3.1 Стена памяти
Арифметика ускорителей исторически опережала bandwidth и ёмкость памяти. GPU/NPU ждут данные — веса, активации, KV cache между HBM, хостом и узлами. Низкий MFU — купленные FLOPS простаивают. В инференсе длинный KV съедает VRAM — память сжимается раньше «чистой» математики.
3.2 Стена связи
Multi-GPU обучение — sync градиентов, tensor parallel, MoE по intra-/inter-node линкам. Обычный стек:
- PCIe CPU↔ускорители — ограниченный bandwidth, тяжёлые копии;
- NVLink / intra-node — силён в коробке, слабее при переходе между машинами;
- Ethernet / InfiniBand — scale-out, но AllReduce может съедать большую долю шага (часто ~30 % — зависит от топологии).
У кодинг-агентов другое лицо: модель в облачном API, tools на ноутбуке или runner — каждый run_terminal_cmd и чтение репо = RTT × число вызовов. Другой слой, чем NVLink, та же «налоговая задержка». Harness не отменяет физику.
[Приложение] Agent / Harness (ECC)
[Система] Unified bus / память
[Кремний] Плотность τ
↓ ощущаемая стоимость = произведение
4. Lingqu (灵衢) и «незаметная» задержка
Если τ — «как дёшево сложить compute на кристалле», Lingqu (灵衢) / unified bus — «как софт использует стек как одну машину». Публичные нарративы (сверять с актуальными whitepaper’ами):
- Единая семантика памяти — CPU, NPU, ускорители, пулы ближе к одному адресному пространству, меньше явных копий;
- Пулинг и sharing — память и compute по задачам, выше утилизация флота;
- Незаметная задержка — не ноль в физике, но sync, скрываемый пайплайном.
Для флагманского обучения: номинальные FLOPS × утилизация → меньше долларов за run — τ на die, Lingqu на fabric, множители.
Для прод-агентов вы покупаете API, а не кластер. Более дешёвый стабильный инференс в масштабе — ваш ценник за миллион токенов, пока Джевонс не вернёт спрос.
5. Если дешевеют и compute, и fabric
Когда токены дешевеют и кластеры меньше простаивают, первая волна — не «меньше агентов», а агенты, которые всегда включены, параллелят сильнее, специализируются:
| Форма | Почему | Связь |
|---|---|---|
| Агенты 24/7 | Низкая предельная стоимость | Облачный Mac, OpenHuman |
| Мульти-агенты | Дешёлая связь | ECC, OpenClaw |
| Малый локально + большой в облаке | Частое vs редкое | Ноутбук + Mac mini |
| Агенты в CI/CD | Каждый коммит | macOS runner |
Следующий всплеск — не обязательно «ещё больше одна модель», а compute как коммунальная услуга: harness решает, как тратить; шина и τ — насколько это рационально.
6. Apple Silicon, облачный Mac, счёт агента
Большинство читателей Nuvcloud делают macOS / Xcode / always-on агентов, а не GPU-мегакластеры. Два вывода:
- Unified memory на десктопе. Apple Silicon — CPU, GPU, Neural Engine, RAM в одном пакете; Mac mini удивляет на части agent-side задач по ватту.
- Счёт = API/токены + машина + простои. ECC/OpenClaw на всегда включённом облачном Mac mini — стабильный compute, фиксированный egress, диск; меньше дорогих перезапусков из-за сна ноутбука.
Практика: один и тот же агент локально и в облаке за день; журнал токенов, времени, ретраев; сравнение с ценами Mac mini (TCO). Harness (ECC) — меньше объездов; облачный Mac — меньше обрывов; τ и Lingqu опускают отраслевые кривые — вместе это «compute-власть» эпохи агентов.
Агенты 24/7: выделенный облачный Mac mini под compute и задержку
Кривые τ — про отрасль; вам нужны машины под агентов 24/7. Nuvcloud M4 Mac mini: bare-metal macOS, SSH/VNC, регионы, день/неделя/месяц — с ECC и OpenClaw.
Прогоните реальный агентный сценарий посуточно — тарифы Nuvcloud.