模型降價,並不等於 Agent 降價。昨天我們拆解了 ECC(Everything Claude Code) 這類 Harness:讓 Claude Code、Cursor Agent 在複雜工程任務裡少迷路、少越權、能跨會話記住約束。但 Harness 管的是應用層的「執行力」——每一輪推理、每一次 tool call、每一段變長的上下文,仍然要消耗算力與時間。
今天把鏡頭下移一層,先回答一個基礎問題:τ 是什麼,它和 Agent 帳單有什麼關係? 讀完下面這一節,再去看 Agent 為何特別耗算力、靈衢如何補 τ 沒蓋到的那一半,脈絡會清楚很多。
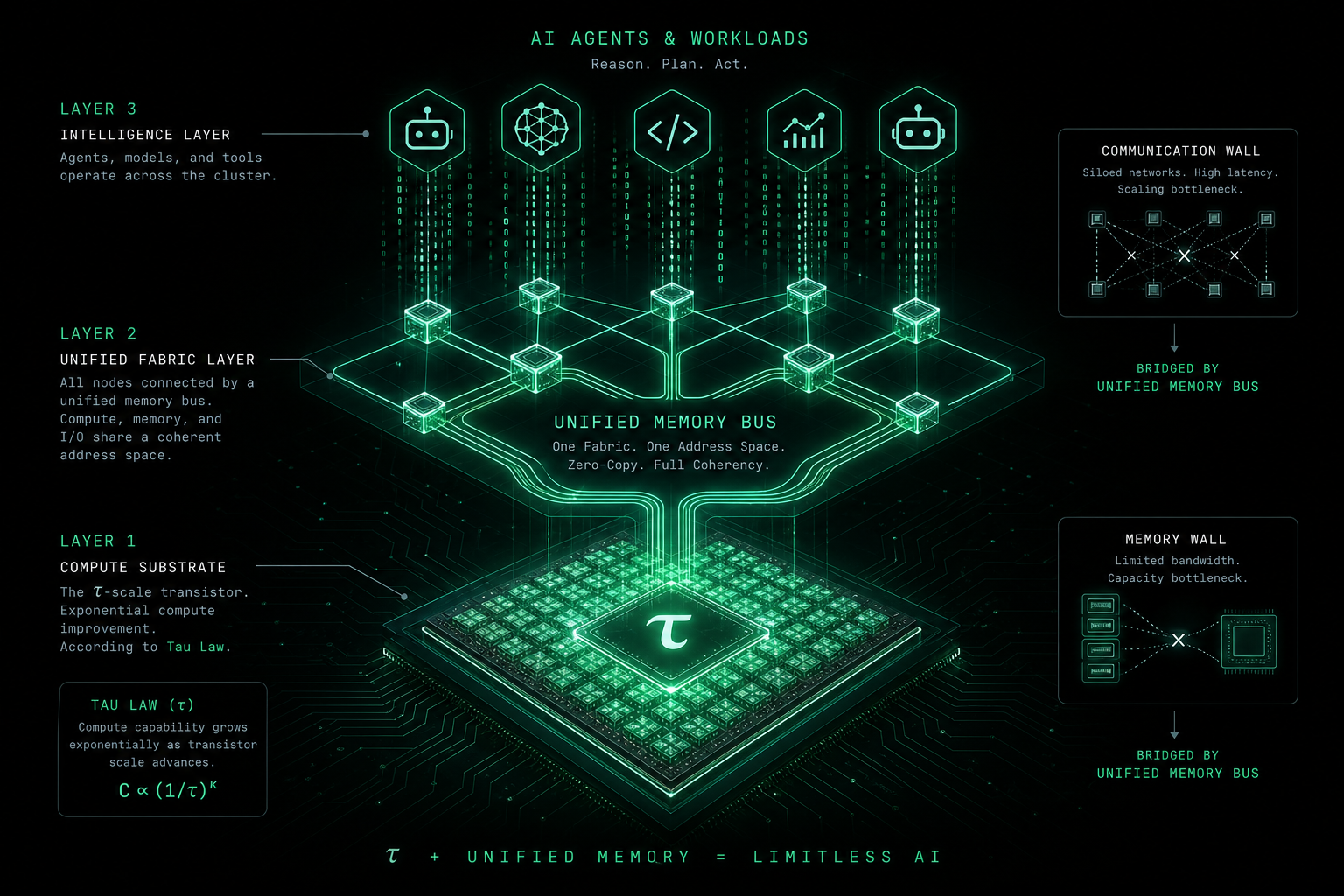
先認識 τ:韬(τ)定律是什麼?
這裡的 τ(讀作「濤」,希臘字母 tau)在近年 AI 基礎設施討論裡,常與中文「韬」並提——韬(τ)定律。它不是寫進教科書的物理公式,也不是用一句話取代摩爾定律;更接近產業界對一條長期供給側趨勢的概括,核心大意可以拆成三句話:
- 電晶體(或等效算力單元)會繼續變多、變密、變便宜——製程與封裝演進,讓單位面積能承載的有效算力長期壓低成本曲線。
- 密度走向「更均一、更可擴展」——不只追求峰值,而是讓算力、記憶體、互聯在系統級更容易池化與複用(為大規模 AI 叢集打底)。
- AI 時代的競爭焦點從「有沒有卡」轉向「卡有沒有在幹活」——單卡標稱 FLOPS 越來越高,若記憶體頻寬、機間通訊跟不上,使用者體感仍是慢與貴。
若你熟悉摩爾定律(約每 18–24 個月電晶體數量翻番),可以這樣理解二者關係:摩爾定律描述的是整合度隨時間爬升;韬(τ)定律在公開敘事裡更強調AI 算力供給的可持續性與均質化——在密度繼續走高的前提下,討論「同樣一美元能買到多少有效推理/訓練算力」,以及這套供給能否撐住 Agent、大模型訓練等常駐型、高頻寬型負載。部分廠商白皮書會用 τ 指代這條成本曲線下斜的斜率;本文沿用業界通俗說法,不綁定某一家的獨家定義。
| 對比項 | 摩爾定律(經典敘事) | 韬(τ)定律(產業敘事) |
|---|---|---|
| 關注點 | 晶片上能堆多少電晶體 | AI 場景下單位算力成本與系統可擴展性 |
| 典型問法 | 「下一代製程何時量產?」 | 「同樣預算能否跑更多 token/更大叢集?」 |
| 對 Agent 的含義 | 間接:推理晶片會更強 | 直接:API 單價長期有下行空間——但需求可能漲得更快 |
| 沒解決的問題 | 記憶體牆、通訊牆、軟體利用率 | 同樣需要靈衢等統一互聯補上 |
對開發者而言,記住 τ 的實用結論即可,不必背公式:
- 供給側: 長期看,同樣美元買到的算力(或 token 配額)傾向變多——這是「算力即權力」裡權力可能擴散的前提。
- 需求側: Agent 把算力從「偶爾問一次」變成「長時間占用+多輪 tool」——總帳單=單價×用量,用量可能超線性成長。
- 系統側: τ 主要改善「矽片上能多算」;記憶體牆、通訊牆要靠統一匯流排(如靈衢)和軟體棧——否則會出現「晶片更強,利用率仍低」的空轉。
下文順序:先說明 Agent 為何特別耗算力 → 再講 τ 降單價時為何總帳單仍可能上漲(傑文斯效應)→ 記憶體牆/通訊牆 → 靈衢如何追求「無感延遲」→ 最後收束到雲端 Mac 與 Harness 分工。
1. 現代 AI Agent 為什麼「貪吃」算力?
傳統 Copilot 式補全,本質是一次性推理:你給一段上下文,模型回一段程式碼。Claude Code、Codex CLI、Cursor Agent 則把互動變成長時間占用型負載:規劃 → 讀檔 → 執行命令 → 看結果 → 再規劃,循環多輪;每一輪都要把不斷膨脹的上下文塞進模型視窗。
| 維度 | 傳統補全/Chat | 編碼 Agent(Claude Code 類) |
|---|---|---|
| 呼叫形態 | 單次問答 | 多步 plan → tool → 再推理(循環) |
| 上下文範圍 | 當前檔案或短片段 | 倉庫級檢索+記憶+終端日誌 |
| 失敗與重試 | 重寫一句 | 重跑整條流水線,token 成倍疊加 |
| 運行時長 | 秒級 | 分鐘到小時級(長任務、CI 聯動) |
| Harness 的作用 | — | 減少無效輪次,但不消除每輪仍要算 |
因此,Agent 把算力需求從「峰值算一下」推成「常駐服務+高頻小請求」。這和訓練千億參數模型不同——訓練要的是叢集 FLOPS 與顯存容量;生產側 Agent 還要疊加尾延遲:你等的不只是模型想多久,還有工具執行、網路 RTT、磁碟 I/O。ECC 的 Skills/Instincts 能砍掉浪費的回合,但若任務本身就要跑五十輪,五十輪的成本仍在。
2. 「供需矛盾」:τ 把單價打下來,需求為何反著長?
若 τ 所描述的成本曲線成立,同樣美元能買到的推理算力在長期看應當越來越多。矛盾出在需求側——Agent 的需求函數更接近超線性:
- 模型越便宜,團隊越敢把「整倉重構」「全量測試矩陣」交給 Agent;
- Harness 越成熟,人越敢開 7×24 常駐任務(對齊 OpenHuman 的 auto-fetch、OpenClaw 的 CI 觸發);
- 上下文視窗越大,單次會話塞進的歷史越多,輸入 token 與輸出 token 同步膨脹。
所以「算力即權力」不是煽情標題,而是帳單結構:誰付得起長期占用 GPU/NPU/API 配額,誰就能把自動化推到競爭對手推不動的粒度。τ 定律若只降低「每 token 標價」,而不降低「每個工程師每天敢燒多少 token」,總支出仍可能創新高。
3. 記憶體牆與通訊牆:貴的不只是晶片,還有「等」
訓練與推理叢集裡,瓶頸早已不只在單卡峰值算力。產業文獻與廠商白皮書反覆提到兩面「牆」:
3.1 記憶體牆(Memory Wall)
算力晶片的算力增速長期快於記憶體頻寬與容量的增速。結果是:GPU/NPU 經常在等資料——權重、激活、KV cache 在 HBM、主機記憶體、甚至跨節點之間搬移。算力利用率(MFU)上不去,等於你買的 FLOPS 有相當比例在空轉。對大模型推理而言,長上下文 KV cache 占顯存,批次大小與並發受限,進一步放大「記憶體比算力更緊」的矛盾。
3.2 通訊牆(Communication Wall)
多卡訓練時,梯度同步、張量並行、專家並行(MoE)都依賴機內與機間互聯。傳統方案大致是:
- PCIe:CPU 與加速器之間頻寬、延遲相對有限,資料拷貝語意重;
- NVLink/機內高速互聯:同機 GPU 之間較好,但跨機仍要走上層網路,軟體棧常把多卡呈現為「多台設備」;
- 乙太/InfiniBand 叢集網:擴展性強,但 AllReduce 等集合通訊在大規模下可占訓練步驟的顯著比例(業界案例中單步通訊占比可達三成量級,具體隨模型與拓撲而異)。
對編碼 Agent 而言,通訊牆還有另一張臉:Agent 在筆電上跑,模型在雲端 API,工具在本地或遠端 Runner——每一次 run_terminal_cmd、每一次讀倉庫,都是網路 RTT × 呼叫次數 的疊加。這和訓練叢集的 NVLink 不是同一層問題,但同屬「延遲稅」:Harness 再強,也消不掉物理等待。
[應用] Agent / Harness(ECC) → 少無效輪次
[系統] 統一匯流排/統一記憶體語意 → 少拷貝、少同步等待
[晶片] τ 曲線下的電晶體密度 → 單瓦特更多算力
↓ 三者相乘,才等於「體感成本」
4. 靈衢與「無感延遲」:τ 定律在系統層怎麼落地?
若 τ 定律回答「矽片上能多便宜地堆算力」,靈衢(Lingqu)/統一匯流排(Unified Bus) 一類架構回答「堆出來的算力如何被一整坨軟體用起來」。公開材料中的核心敘事包括(具體參數以廠商發布為準):
- 統一記憶體語意:CPU、NPU、加速器、記憶體池在位址空間或存取語意上更接近「同一台機器」,減少顯式拷貝與反覆 pin/unpin;
- 池化與共享:記憶體、算力可按任務動態劃撥,提高叢集級利用率;
- 無感延遲的目標:並非物理上零延遲,而是讓同步與等待降到流水線可掩蓋、業務不可感的程度。
對旗艦大模型訓練,這意味著:同樣規模的叢集,有效吞吐可能更接近「標稱算力×更高利用率」,單位訓練任務的美元成本有下降空間——這是 τ(電晶體側)與靈衢(互聯側)的乘數關係,而非替代關係。
對Agent 生產,靈衢一類能力間接體現在:更低延遲的推理服務、更大並發下的穩定尾延遲、更便宜的專用推理卡。Agent 用戶未必買叢集,但會買「API 背後那套基礎設施是否划算」——基礎設施越省,API 標價越有降價空間,而傑文斯效應又會把需求推回去。
5. 若算力與互聯雙降,下一個爆發的形態是什麼?
當「每 token 更便宜」且「叢集更少空轉」同時發生時,最先爆發的往往不是沒有 Agent,而是更敢常開、更敢並行、更敢專屬化的 Agent:
| 形態 | 為何成立 | 與現狀的銜接 |
|---|---|---|
| 7×24 常駐 Agent/數位員工 | 邊際成本夠低,才值得一直跑 | 雲端 Mac、OpenHuman Memory Tree |
| 多 Agent 編排與分工 | 通訊與推理便宜,才值得「多角色開會」 | ECC Skills 組合、OpenClaw 分機 |
| 小模型本地+大模型雲端混合 | 高頻小任務下沉,低頻難任務上雲 | 筆電+雲端 Mac mini 分工 |
| Agent 深度嵌入 CI/CD | 每次提交都跑一輪審查/測試生成 | 自建 macOS Runner、Webhook 流水線 |
換句話說:下一個浪潮可能不是「更大的單一模型」,而是算力被當成水電一樣常駐消耗的應用層——Harness 定義怎麼花得明白,匯流排與 τ 曲線定義花得是否划算。
6. 收束:Apple Silicon、雲端 Mac 與 Agent 帳單
Nuvcloud 讀者多數在做 macOS/Xcode/常駐 Agent,未必直接採購 GPU 訓練叢集。但仍可從本文帶走兩點:
- 單機也有「統一記憶體」紅利。 Apple Silicon 把 CPU、GPU、Neural Engine 與統一記憶體放在同一封裝裡,對本地推理、媒體處理、中等規模模型,本質是「小號的統一記憶體架構」——適合解釋為什麼 Mac mini 跑某些 Agent 輔助任務「性夠用且能效好看」。
- Agent 帳單=API/token+機器時間+中斷成本。 把 Claude Code、ECC、OpenClaw 放在常線上的雲端 Mac mini 上,買的是穩定算力、固定出口 IP、可擴容磁碟,避免筆電合蓋、家用寬頻抖動導致的長任務失敗重跑——失敗重跑往往比月租更貴。
建議實操:選一天把同一 Agent 任務分別在本地與雲端各跑一遍,記錄總 token、總牆鐘時間、失敗重試次數,再對照 Mac mini 定價 做 TCO。Harness(ECC)負責少繞路;雲端 Mac 負責少中斷——底層 τ 與靈衢負責整個行業成本曲線下移,三者疊在一起,才是 Agent 時代真正的「算力權力」分配。
Agent 要常線上:用獨享雲端 Mac mini 接住算力與延遲
τ 曲線與統一匯流排討論的是產業級成本;你的團隊今天面對的是每台機器是否在 7×24 穩定跑 Agent。Nuvcloud M4 Mac mini 提供裸機 macOS、SSH/VNC、多地區節點與日/週/月計費——與 ECC、OpenClaw 搭配。
先日租跑一輪真實 Agent 任務,對照 token 與時間帳單——查看 Nuvcloud 套餐。