模型降价,并不等于 Agent 降价。昨天我们拆解了 ECC(Everything Claude Code) 这类 Harness:它让 Claude Code、Cursor Agent 在复杂工程任务里少迷路、少越权、能跨会话记住约束。但 Harness 管的是应用层的「执行力」——每一轮推理、每一次 tool call、每一段上下文,仍然要消耗算力与时间。
今天把镜头下移一层,先回答一个基础问题:τ 是什么,它和 Agent 账单有什么关系? 读完下面这一节,再去看 Agent 为何「贪吃」算力、灵衢如何补 τ 没覆盖的那一半,脉络会清楚很多。
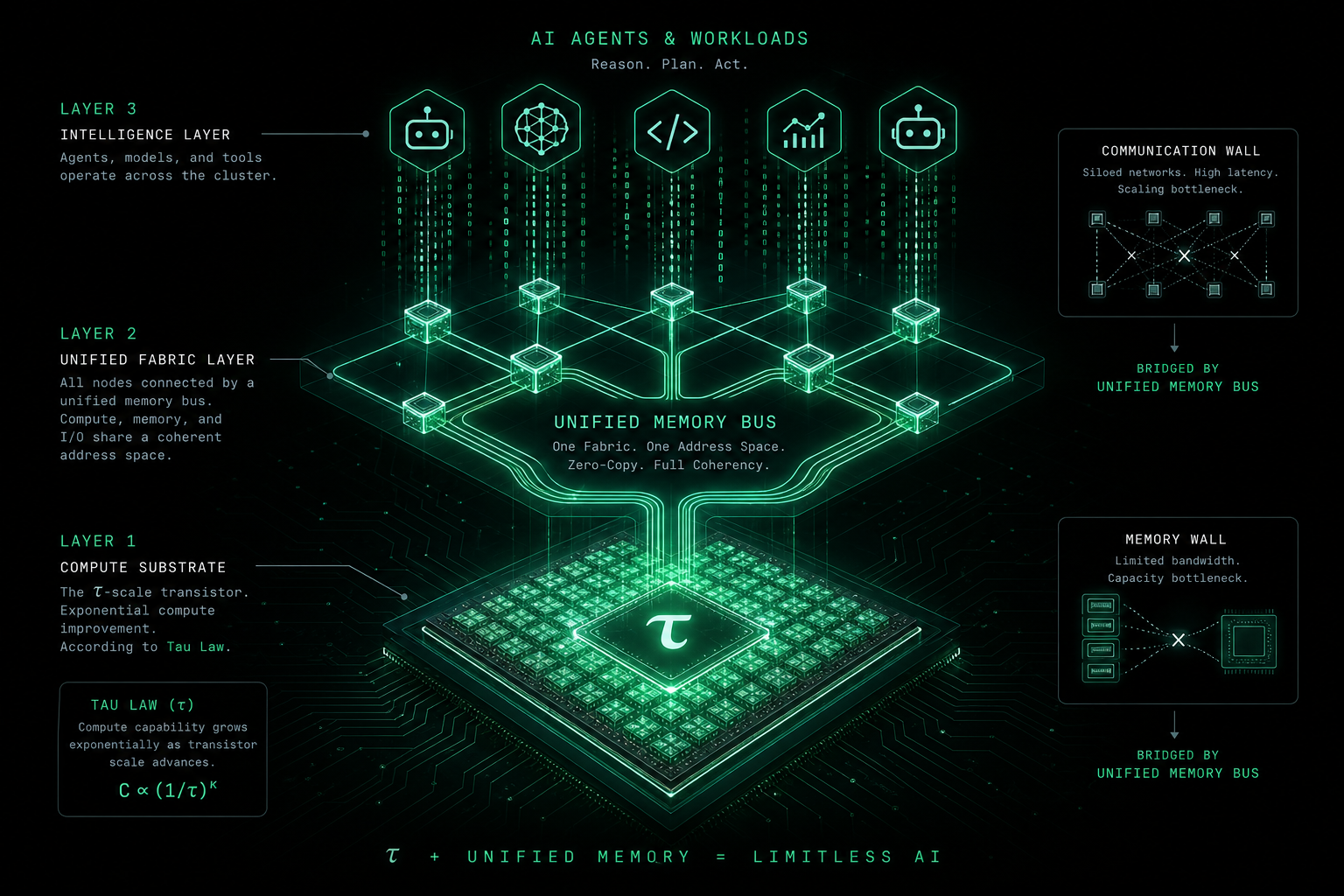
先认识 τ:韬(τ)定律是什么?
这里的 τ(读作「涛」,希腊字母 tau)在近年 AI 基础设施讨论里,常与中文「韬」并提——韬(τ)定律。权威技术背景可参考华为在 IEEE ISCAS 2026 上关于 τ Scaling 的公开阐释(算力供给可持续性与系统均一化等论述)。它不是某条已写入教科书的物理公式,也不是与摩尔定律简单划等号的口号;更接近产业界对一条长期供给侧趋势的概括,核心大意可以拆成三句话:
- 晶体管(或等效算力单元)会继续变多、变密、变便宜——工艺与封装演进,让单位面积能承载的有效算力长期向下压成本曲线。
- 密度走向「更均一、更可扩展」——不只追求峰值,而是让算力、内存、互联在系统级更容易池化与复用(为大规模 AI 集群打底)。
- AI 时代的竞争焦点从「有没有卡」转向「卡有没有在干活」——单卡标称 FLOPS 越来越高,但若内存带宽、机间通信跟不上,用户体感仍是慢与贵。
若你熟悉摩尔定律(约每 18–24 个月晶体管数量翻番),可以这样理解二者关系:摩尔定律描述的是集成度随时间爬升;韬(τ)定律在公开叙事里更强调AI 算力供给的可持续性与均一化——在密度继续走高的前提下,讨论「同样一美元能买到多少有效推理/训练算力」,以及这套供给能否撑住 Agent、大模型训练等常驻型、高带宽型负载。上文华为材料即围绕 τ Scaling 展开;本文在此基础上衔接 Agent 场景,不替代厂商官方技术定义。
| 对比项 | 摩尔定律(经典叙事) | 韬(τ)定律(产业叙事) |
|---|---|---|
| 关注点 | 芯片上能堆多少晶体管 | AI 场景下单位算力成本与系统可扩展性 |
| 典型问法 | 「下一代制程何时量产?」 | 「同样预算能否跑更多 token / 更大集群?」 |
| 对 Agent 的含义 | 间接:推理芯片会更强 | 直接:API 单价长期有下行空间——但需求可能涨得更快 |
| 没解决的问题 | 内存墙、通信墙、软件利用率 | 同样需要灵衢等统一互联补上 |
对开发者而言,记住 τ 的实用结论即可,不必背公式:
- 供给侧: 长期看,同样美元买到的算力(或 token 配额)倾向于变多——这是「算力即权力」里权力可能扩散的前提。
- 需求侧: Agent 把算力从「偶尔问一次」变成「长时间占用 + 多轮 tool」——总账单 = 单价 × 用量,用量可能超线性增长。
- 系统侧: τ 主要改善「硅片上能多算」;内存墙、通信墙要靠统一总线(如灵衢)和软件栈——否则会出现「芯片更强,利用率仍低」的空转。
下文顺序是:先说明 Agent 为何特别耗算力 → 再讲 τ 降单价时为何总账单仍可能上涨(杰文斯效应)→ 内存墙/通信墙 → 灵衢如何追求「无感延迟」→ 最后收束到云端 Mac 与 Harness 分工。
1. 现代 AI Agent 为什么「贪吃」算力?
传统 Copilot 式补全,本质是一次性推理:你给一段上下文,模型回一段代码。Claude Code、Codex CLI、Cursor Agent 则把交互变成长时间占用型负载:规划 → 读文件 → 执行命令 → 看结果 → 再规划,循环多轮;每一轮都要把不断膨胀的上下文塞进模型窗口。
| 维度 | 传统补全 / Chat | 编码 Agent(Claude Code 类) |
|---|---|---|
| 调用形态 | 单次问答 | 多步 plan → tool → 再推理(循环) |
| 上下文范围 | 当前文件或短片段 | 仓库级检索 + 记忆 + 终端日志 |
| 失败与重试 | 重写一句 | 重跑整条流水线,token 成倍叠加 |
| 运行时长 | 秒级 | 分钟到小时级(长任务、CI 联动) |
| Harness 的作用 | — | 减少无效轮次,但不消除每轮仍要算 |
因此,Agent 把算力需求从「峰值算一下」推成「常驻服务 + 高频小请求」。这和训练千亿参数模型不同——训练要的是集群 FLOPS 与显存容量;生产侧 Agent 还要叠加尾延迟:你等的不只是模型想多久,还有工具执行、网络 RTT、磁盘 I/O。ECC 的 Skills/Instincts 能砍掉浪费的回合,但若任务本身就要跑五十轮,五十轮的成本仍在。
2. 「供需矛盾」:τ 把单价打下来,需求为何反着长?
上一节已说:若 τ 所描述的成本曲线成立,同样美元能买到的推理算力在长期看应当越来越多。矛盾出在需求侧——Agent 的需求函数更接近超线性:
- 模型越便宜,团队越敢把「整仓重构」「全量测试矩阵」交给 Agent;
- Harness 越成熟,人越敢开 7×24 常驻任务(对齐 OpenHuman 的 auto-fetch、OpenClaw 的 CI 触发);
- 上下文窗口越大,单次会话塞进的历史越多,输入 token 与输出 token 同步膨胀。
所以「算力即权力」不是煽情标题,而是账单结构:谁付得起长期占用 GPU/NPU/API 配额,谁就能把自动化推到竞争对手推不动的粒度。τ 定律若只降低「每 token 标价」,而不降低「每个工程师每天敢烧多少 token」,总支出仍可能创新高。
3. 内存墙与通信墙:贵的不只是芯片,还有「等」
训练与推理集群里,瓶颈早已不只在单卡峰值算力。行业文献与厂商白皮书反复提到两面「墙」:
3.1 内存墙(Memory Wall)
算力芯片的算力增速长期快于内存带宽与容量的增速。结果是:GPU/NPU 经常在等数据——权重、激活、KV cache 在 HBM、主机内存、甚至跨节点之间搬移。算力利用率(MFU)上不去,等于你买的 FLOPS 有相当比例在空转。对大模型推理而言,长上下文 KV cache 占显存,批大小与并发受限,进一步放大「内存比算力更紧」的矛盾。
3.2 通信墙(Communication Wall)
多卡训练时,梯度同步、张量并行、专家并行(MoE)都依赖机内与机间互联。传统方案大致是:
- PCIe:CPU 与加速器之间带宽、延迟相对有限,数据拷贝语义重;
- NVLink / 机内高速互联:同机 GPU 之间较好,但跨机仍要走上层网络,软件栈常把多卡呈现为「多台设备」;
- 以太 / InfiniBand 集群网:扩展性强,但 AllReduce 等集合通信在大规模下可占训练步骤的显著比例(业界案例中单步通信占比可达三成量级,具体随模型与拓扑而异)。
对编码 Agent 而言,通信墙还有另一张脸:Agent 在笔记本上跑,模型在云端 API,工具在本地或远程 Runner——每一次 run_terminal_cmd、每一次读仓库,都是网络 RTT × 调用次数 的叠加。这和训练集群的 NVLink 不是同一层问题,但同属「延迟税」:Harness 再强,也消不掉物理等待。
[应用] Agent / Harness(ECC) → 少无效轮次
[系统] 统一总线 / 统一内存语义 → 少拷贝、少同步等待
[芯片] τ 曲线下的晶体管密度 → 单瓦特更多算力
↓ 三者相乘,才等于「体感成本」
4. 灵衢与「无感延迟」:τ 定律在系统层怎么落地?
若 τ 定律回答「硅片上能多便宜地堆算力」,灵衢(Lingqu)/ 统一总线(Unified Bus) 一类架构回答「堆出来的算力如何被一整坨软件用起来」。公开材料中的核心叙事包括(具体参数以厂商发布为准):
- 统一内存语义:CPU、NPU、加速器、内存池在地址空间或访问语义上更接近「同一台机器」,减少显式拷贝与反复 pin/unpin;
- 池化与共享:内存、算力可按任务动态划拨,提高集群级利用率;
- 无感延迟的目标:并非物理上零延迟,而是让同步与等待降到流水线可掩盖、业务不可感的程度——训练步之间、推理批之间少「干等互联」。
对旗舰大模型训练(无论闭源下一代还是开源 MoE),这意味着:同样规模的集群,有效吞吐可能更接近「标称算力 × 更高利用率」,单位训练任务的美元成本有下降空间——这是 τ(晶体管侧)与灵衢(互联侧)的乘数关系,而非替代关系。
对Agent 生产,灵衢一类能力间接体现在:更低延迟的推理服务、更大并发下的稳定尾延迟、更便宜的专用推理卡。Agent 用户未必买集群,但会买「API 背后那套基础设施是否划算」——基础设施越省,API 标价越有降价空间,而杰文斯效应又会把需求推回去。
5. 若算力与互联双降,下一个爆发的形态是什么?
当「每 token 更便宜」且「集群更少空转」同时发生时,最先爆发的往往不是没有 Agent,而是更敢常开、更敢并行、更敢专属化的 Agent:
| 形态 | 为何成立 | 与现状的衔接 |
|---|---|---|
| 7×24 常驻 Agent / 数字员工 | 边际成本够低,才值得一直跑 | 云端 Mac、OpenHuman Memory Tree |
| 多 Agent 编排与分工 | 通信与推理便宜,才值得「多角色开会」 | ECC Skills 组合、OpenClaw 分机 |
| 小模型本地 + 大模型云端混合 | 高频小任务下沉,低频难任务上云 | 笔记本 + 云端 Mac mini 分工 |
| Agent 深度嵌入 CI/CD | 每次提交都跑一轮审查/测试生成 | 自建 macOS Runner、Webhook 流水线 |
换句话说:下一个浪潮可能不是「更大的单一模型」,而是算力被当成水电一样常驻消耗的应用层——Harness 定义怎么花得明白,总线与 τ 曲线定义花得是否划算。
6. 收束:Apple Silicon、云端 Mac 与 Agent 账单
Nuvcloud 读者多数在做 macOS / Xcode / 常驻 Agent,未必直接采购 GPU 训练集群。但仍可从本文带走两点:
- 单机也有「统一内存」红利。 Apple Silicon 把 CPU、GPU、Neural Engine 与统一内存放在同一封装里,对本地推理、媒体处理、中等规模模型,本质是「小号的统一内存架构」——适合解释为什么 Mac mini 跑某些 Agent 辅助任务「性能够用且能效好看」。
- Agent 账单 = API/token + 机器时间 + 中断成本。 把 Claude Code、ECC、OpenClaw 放在常在线的云端 Mac mini 上,买的是稳定算力、固定出口 IP、可扩容磁盘,避免笔记本合盖、家用宽带抖动导致的长任务失败重跑——失败重跑往往比月租更贵。
建议实操:选一天把同一 Agent 任务分别在本地与云端各跑一遍,记录总 token、总墙钟时间、失败重试次数,再对照 Mac mini 定价 做 TCO。Harness(ECC)负责少绕路;云端 Mac 负责少中断——底层 τ 与灵衢负责整个行业成本曲线下移,三者叠在一起,才是 Agent 时代真正的「算力权力」分配。
Agent 要常在线:用独享云端 Mac mini 接住算力与延迟
τ 曲线与统一总线讨论的是行业级成本;你的团队今天面对的是每台机器是否在 7×24 稳定跑 Agent。Nuvcloud M4 Mac mini 提供裸金属 macOS、SSH/VNC、多地区节点与日/周/月计费——与 ECC、OpenClaw 搭配时,把「算力 + 不断线」握在自己手里。
先日租跑一轮真实 Agent 任务,对照 token 与时间账单——查看 Nuvcloud 套餐。